1. 缓存设计
Redis 作为高性能的内存数据库,具有较高的读写速度和并发性能,常常被用作于系统的缓存。通过将频繁访问的热点数据保存在 Redis 中,可以减少底层的磁盘数据库的直接访问次数,从而以提升系统的整体性能、稳定性和吞吐量。
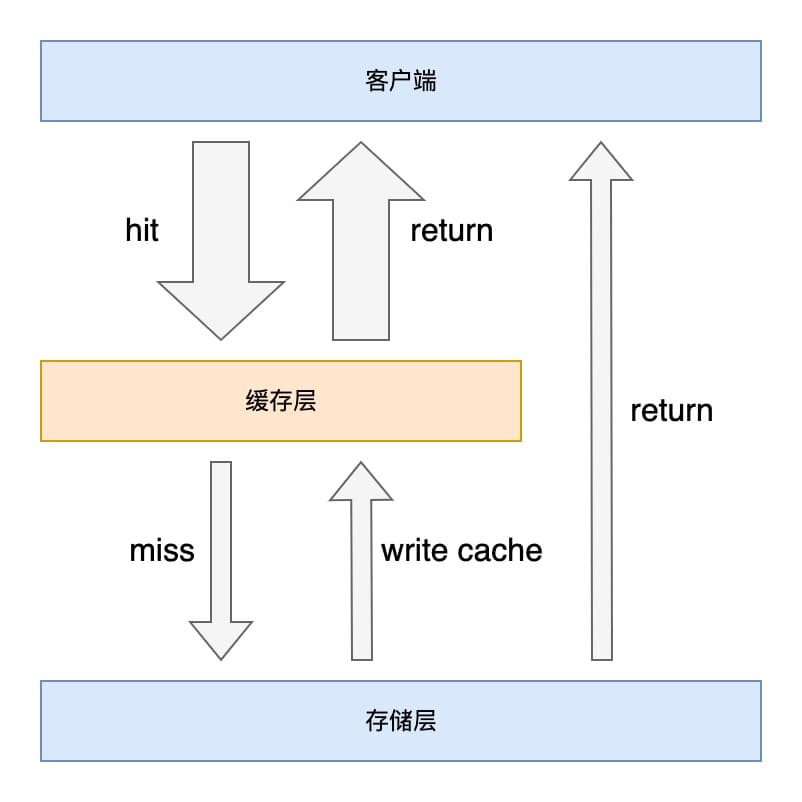
将 Redis 作为底层数据库的缓存,带来了以下的收益:
- 加速读写速度,因为 Redis 的数据完全存在内存,相比基于磁盘的数据库有更高的读写性能;
- 降低数据库负载,将热点数据保存在缓存中,使得大部分数据读取直接在缓存层就能返回,减少了数据库的访问量;
但这也带来了一些成本问题:
- 数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性;
- 代码维护成本:代码需要同时处理缓存层和存储层的逻辑;
- 运维成本:Redis Cluster 部署的运维成本;
2. 缓存更新
2.1 缓存策略
缓存中的数据都是有生命周期的,需要在指定时间后删除或更新,缓存中的数据会和数据源有一段时间窗口的不一致,需要使用某种策略进行更新。
要求高一致性的业务可以结合使用主动更新和超时剔除,允许低一致性的业务可以配置最大内存和对应的淘汰策略。
惰性加载
在缓存失效或未命中时,只有当有请求到达时,才从后端数据库获取数据,然后将数据存入缓存中。
这种策略可以延迟数据加载的时间,只在需要的时候才去获取数据,适用于数据更新较慢或对实时性要求不高的场景。
预先加载
在系统启动或定时任务触发时,提前讲数据加载到缓存中。
通过预先加载热门数据,可以避免缓存失效或未命中时访问底层数据库,从而提高系统的响应速度和性能,适用于数据更新较少且热点数据固定的场景。
主动更新
用在对数据一致性要求高的应用场景,在真实数据更新后哦立即更新缓存数据。还应该设置一定的超时时间,以避免主动更新发生问题时,缓存数据长时间未更新。
维护成本比较高,需要开发者自己完成更新。
异步刷新
在缓存失效或未命中时,通过异步操作从后端数据库中获取数据并更新缓存。
通过异步任务或消息队列,将缓存更新操作与实际请求解耦,从而提高系统的并发处理能力和响应速度,适合于对实时性要求较高、数据更新频繁的场景。
超时剔除
给缓存数据设置过期时间,让它在过期时间后自动删除。数据过期后再次请求对应数据时,会重新写入缓存和设置过期时间。
实际实现中,对于到达超时时间的 key,Redis 不会立刻主动清理,而是通过异步线程去清理。读取逻辑在判断该键的过期时间在当前之前,对于 Redis 来说就是已删除的数据直接跳过。
当数据库更新了而未主动更新缓存,这种方式会存在一段时间窗口内缓存和数据库的数据不一致。
最大内存和内存淘汰策略算法
通过配置 maxmemory 配置 Redis 使用的最大内存,maxmemory-policy 配置内存达到预置后的内存淘汰策略。
内存淘汰策略:
- 内存不足时报错:noeviction(默认策略)
- 从设置了过期时间的键中选择淘汰:volatile-lru(最近最少使用)、volatile-lfu(最不经常使用)、volatile-random(随机选择淘汰)、volatile-ttl(离过期时间最短的淘汰)
- 从所有键中淘汰:allkeys-lru、allkeys-lfu、allkeys-random
这种方式的数据一致性最差。
2.2 数据一致性
使用 Redis 作为底层的 MySQL 数据库的缓存时,Redis 作为缓存提升数据访问的性能,MySQL 数据库用来持久化数据,保证数据的可靠性。
数据的不一致通常发生在数据有变更的时候,此时需要同时操作缓存和数据库,有可能出现其中一方更新失败,或者存在只更新了一方的时间差。Redis 缓存是通过牺牲强一致性来提高读性能的,我们只能尽量追求不一致的时间和范围更小,以及最终一致性。
为了实现强一致性,可以通过强一致性算法或者分布式锁来实现,或者干脆直接不使用缓存。而在实际应用中,很难保证缓存和数据库中的数据完全一样,我们需要尽可能让缓存的数据和数据库在绝大部分时间内保持一致,并保证最终的完全一致。
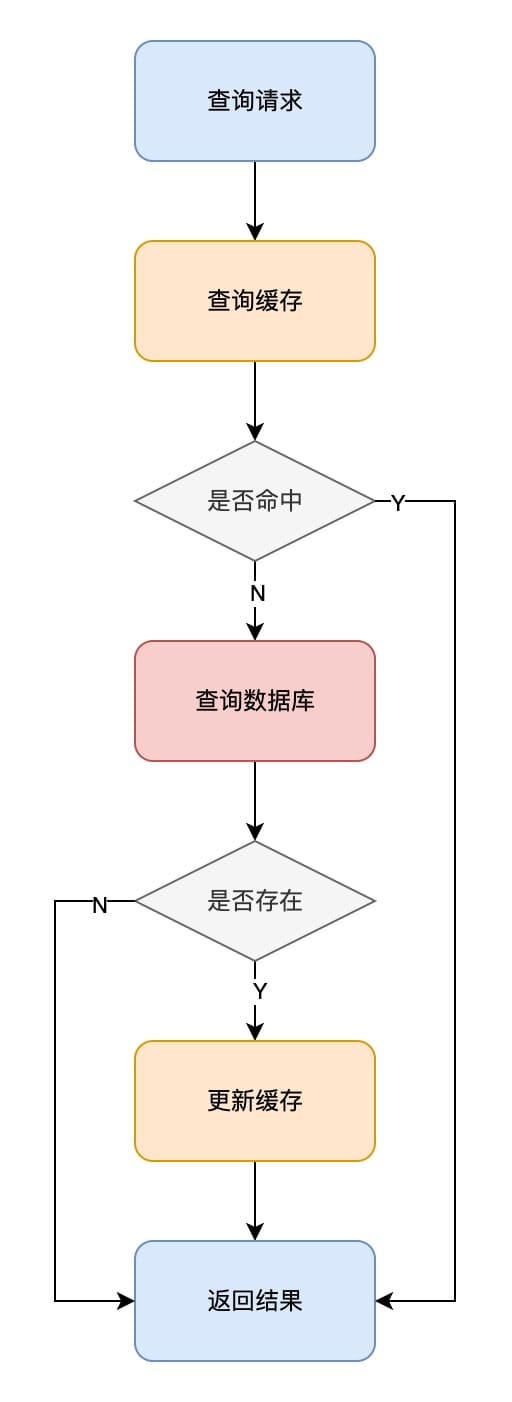
2.2.1 查询请求
Cache-Aside Pattern(旁路缓存模式)中,读取缓存、读取数据库、更新缓存操作都是在应用中完成的。
对于查询请求,先去查询缓存,缓存存在则直接返回。
如果缓存不存在,再去查询数据库,如果数据库也不存在则直接返回,否则更新缓存后返回。
2.2.2 更新请求
更新请求对于缓存和数据库有以下四种做法:
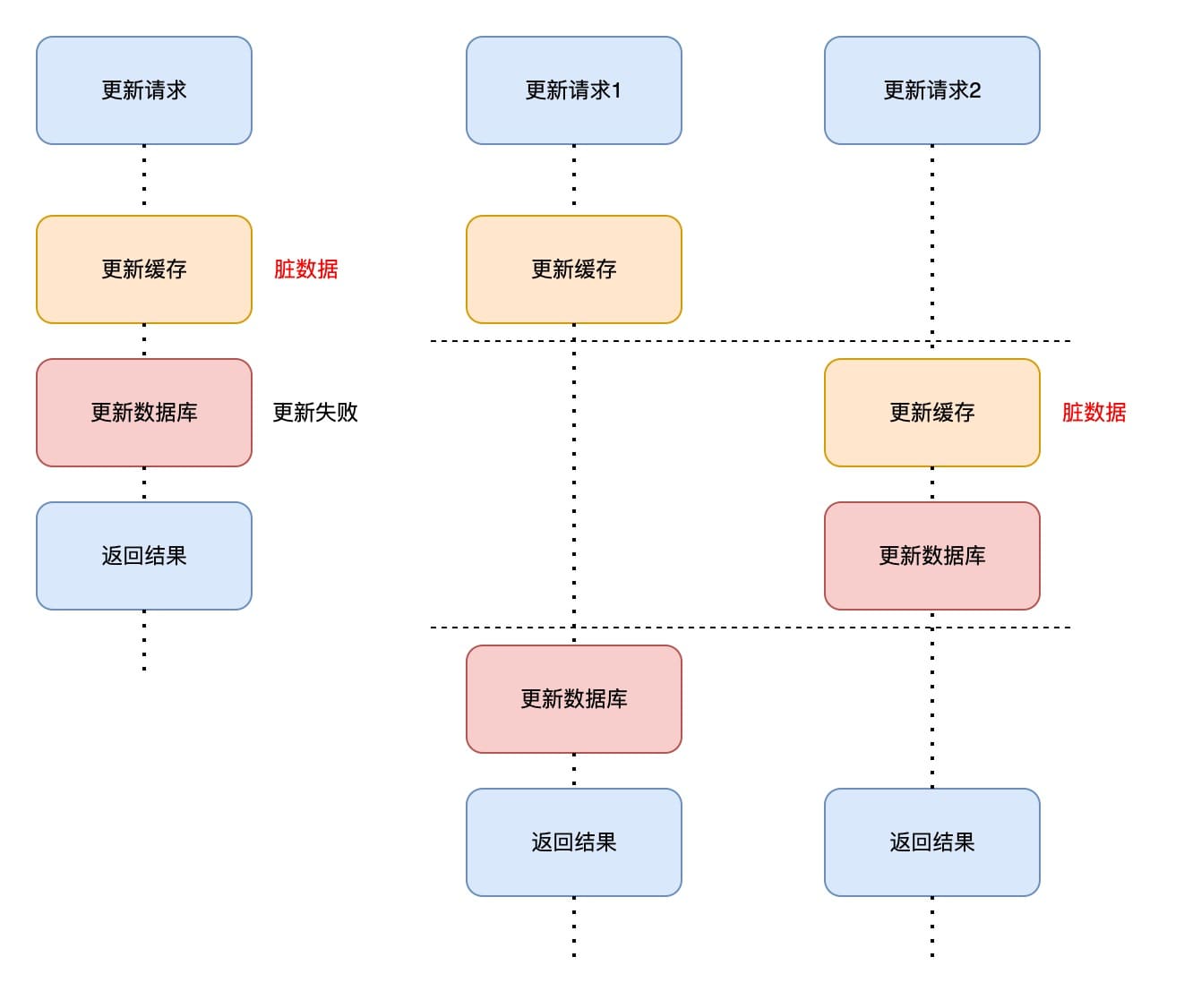
方法一、先更新缓存,再更新数据库
这种方法如果在更新缓存后,更新数据库失败,会造成缓存中的数据为脏数据。
两个更新请求的并发也有可能产生数据不一致。
- 更新请求1先更新缓存;
- 这时候更新请求2到来,更新了缓存和数据库;
- 更新请求1接下来完成更新数据库,此时缓存是更新请求2设置的值,属于脏数据;
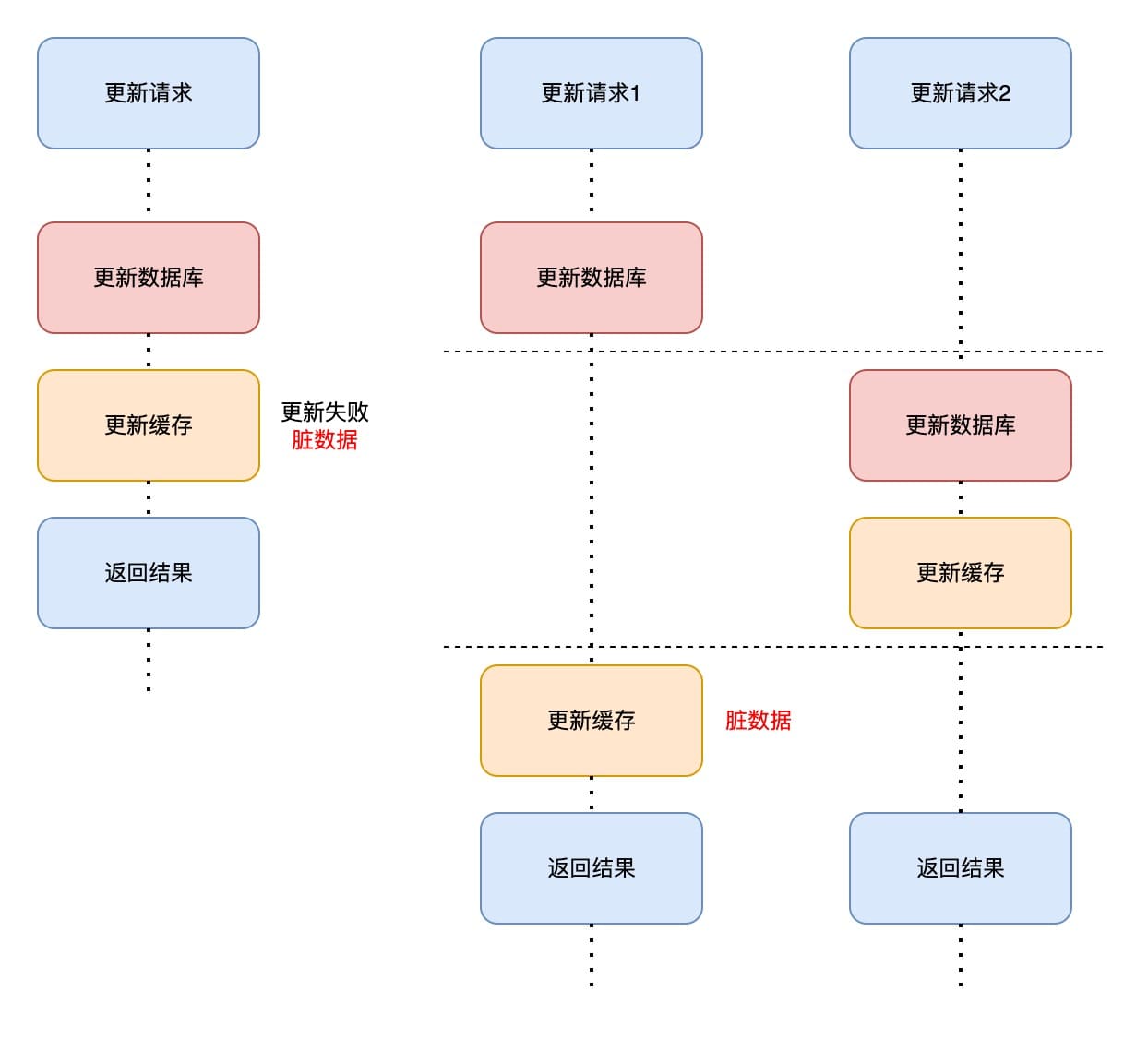
方法二、先更新数据库,再更新缓存
这种方法如果在更新数据库后,更新缓存失败,会造成缓存中的数据为脏数据。
两个更新请求的并发也有可能产生数据不一致。
- 更新请求1先更新数据库;
- 这时候更新请求2到来,更新了数据库和缓存;
- 更新请求1接下来完成更新缓存,此时的缓存属于脏数据;
方法三:先删除缓存,再更新数据库
这种方法在并发读写的时候容易导致缓存不一致。
- 更新请求首先将缓存删除;
- 这时候有一个查询请求,查询缓存未命中,于是查询数据库,然后将值更新至缓存;
- 更新请求接着更新数据库,此时缓存中的数据便成了脏数据;
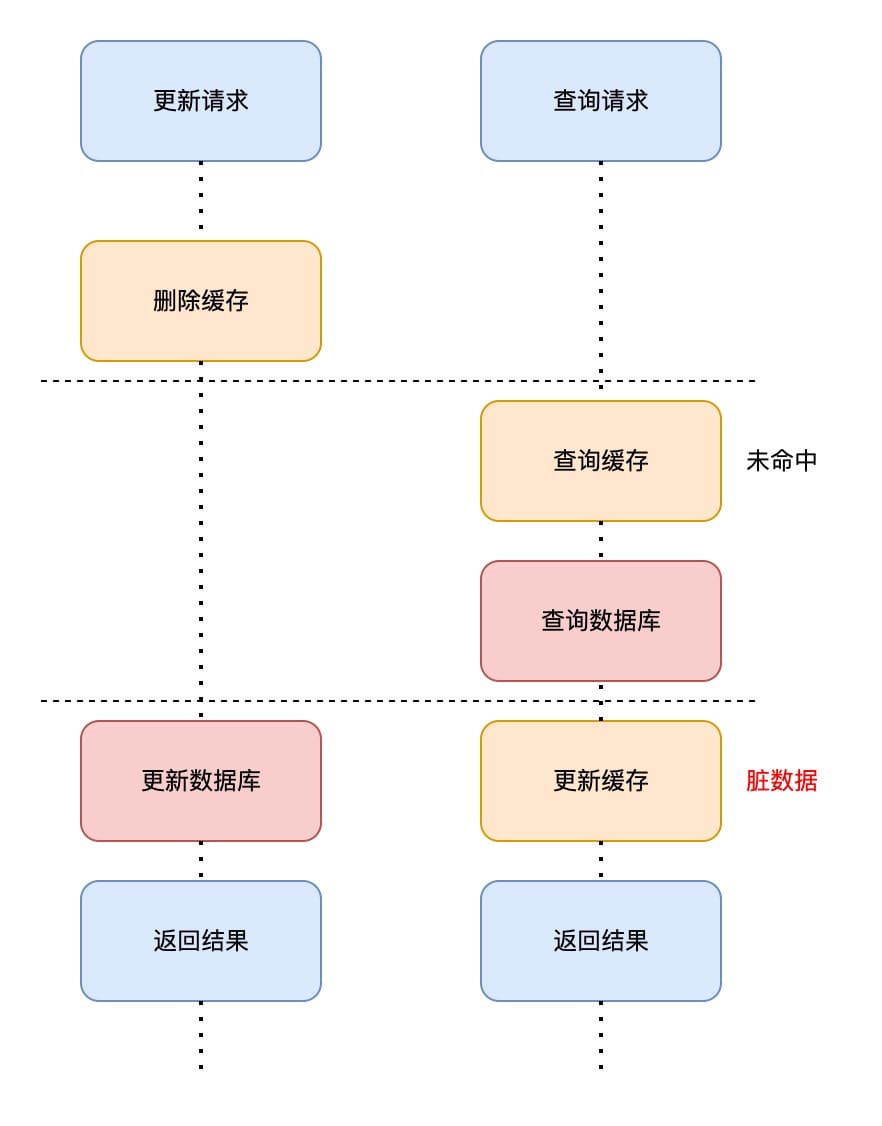
方法四:先更新数据库,再删除缓存
这种方法在并发读写的时候,可能会出现短暂的不一致,大部份业务场景问题不大,优先推荐使用。
- 更新请求首先更新数据库,然后将缓存删除;
- 查询请求1在删除缓存前查询缓存命中,返回旧数据;
- 查询请求2在删除缓存后查询缓存未命中,查询数据库,然后将值更新至缓存,返回新数据;
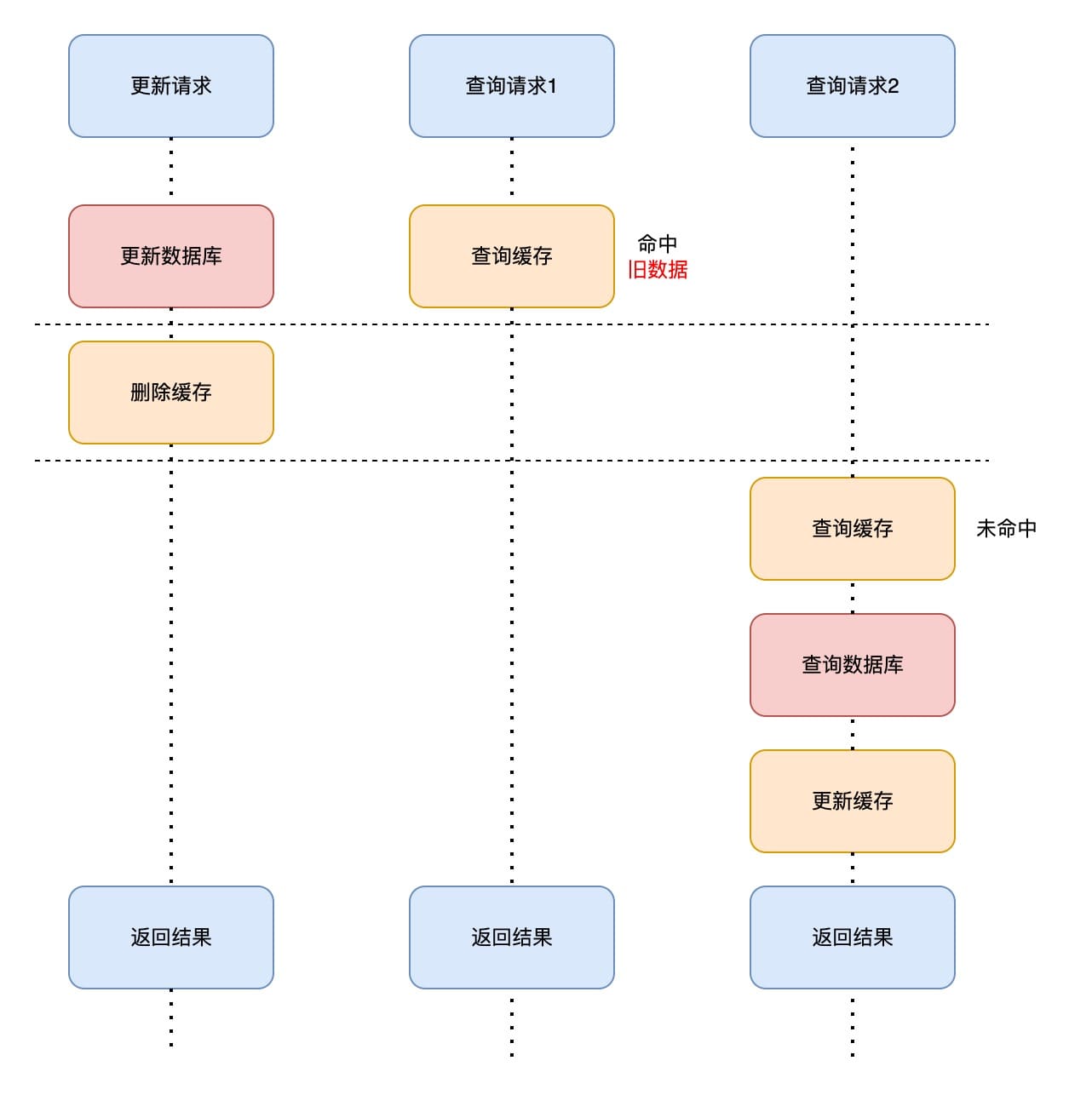
这种方案中,我们要保证成功删除缓存,因为如果删除缓存失败,缓存中就会保留旧数据,产生数据不一致。可以通过重试机制,定时重试或者将删除写入消息队列异步删除,以确保缓存的删除。
方法五:延迟双删
删除缓存,更新数据库,休眠一段时间后再次删除缓存。
第一次删除是为了避免高并发状况下的缓存不一致,更新后休眠一段时间是为了留时间给查询请求将旧数据写到缓存,第二次删除可以确保删掉旧数据。
这个休眠时间不好估计,方案也过于复杂,因此不推荐使用。
方法六:消息队列+订阅binlog
更新操作只需要操作数据库即可。
一个进程通过订阅 binlog 的方式,获取变更信息,插入消息队列。另一个进程消费消息,进行缓存的更新,并且可以加上一定的重试。
这种方式将更新数据库和更新缓存进行了解耦,但会造成系统的复杂度上升,部署和维护成本也更高,可以酌情考虑使用。
3. 问题与优化
3.1 缓存穿透
缓存穿透是指查询一个不存在的数据,缓存层和存储层都无法命中,将返回空结果。缓存穿透导致对不存在的数据的每次请求都要走到存储层,失去了缓存保护后端存储的意义,可能会使后端存储负载变大,甚至挂掉。
缓存空对象
当存储层不命中时,仍将空对象保留到缓存层,后面再次获取这个数据将直接在缓存中获取到。
![]()
这个方式也带来了一些问题:
- 将空值保存到缓存可能会令缓存占用更多的内存空间,针对这个可以给缓存的空对象设置较短的过期时间,以自动清除;
- 可能造成缓存层和数据层的数据不一致,如缓存了空对象后,在存储层添加了这个数据,此时缓存和存储层会有数据不一致,需要其他方式清理缓存中的空对象;
布隆过滤器
布隆过滤器(bloom filter)是一种高效的概率型数据结构,用于快速判断一个元素是否存在于集合中,它是通过 bitmap 实现的。
在访问缓存层之前添加一层布隆过滤器作为拦截,布隆过滤器加入了所有的 key 的集合,存储层新增的数据也要加入布隆过滤器中,如果在布隆过滤器中查不到则表示不存在该 key,可以直接返回空对象。
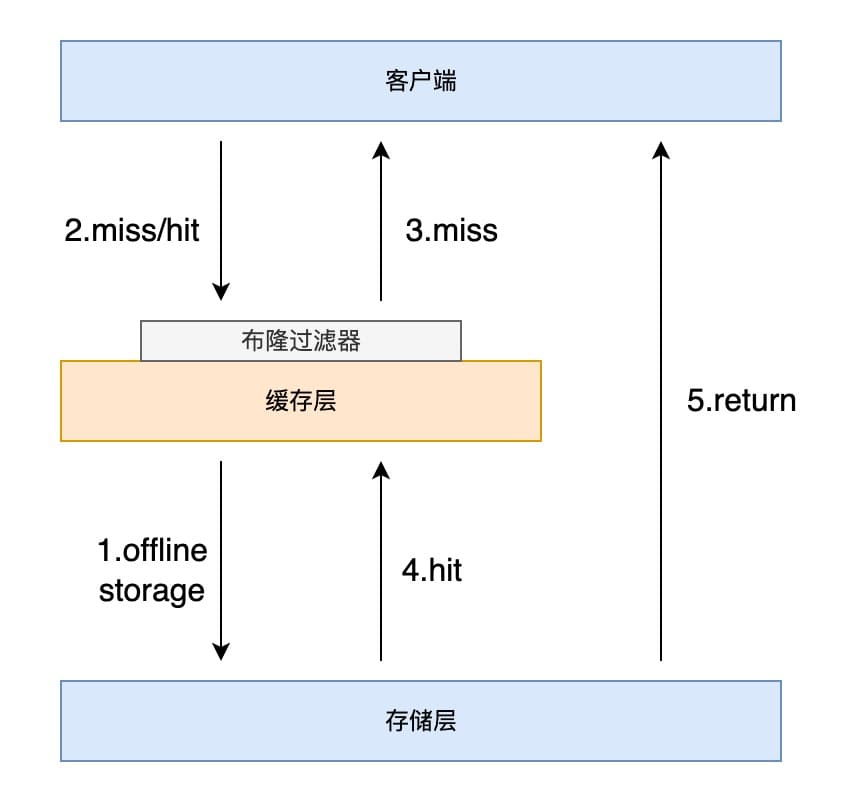
这种方式适用于数据命中率底、数据相对固定、实时性低的应用场景。
3.2 缓存击穿
Redis 的一个 key 属于热点 key,对它的读取并发量非常大,在这个 key 失效的瞬间,大量的请求会全部到达数据库,造成数据库压力徒增甚至压垮数据库。
解决这个问题的方法:
- 互斥锁:通过互斥锁,只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据,该方法有可能存在死锁和线程池阻塞的风险;
- 定时更新:通过定时任务去重新设置热点数据的过期时间;
- 永不过期:不设置过期时间,热点 key 就不会过期,另外使用单独线程定时更新缓存,该方式可能会出现数据不一致的情况,代码复杂度会增大;
3.3 缓存雪崩
缓存层承载着大量的请求,保护着存储层。当 Redis 出现宕机或者大面积的 key 同时过期,会导致大量请求同时打到数据库,存储层的调用量暴增,从而造成级联宕机。
预防和解决雪崩问题的方法:
- 通过 Redis Sentinel 或 Redis Cluster 实现 Redis 服务的高可用,减少单点故障风险;
- 限流和降级:对重要的资源如 Redis 和 MySQL 进行隔离部署和运行,避免部分资源对其他资源的影响,当某些资源不可用时对服务进行降级,保证基础功能的可用;
- 对缓存设置的过期时间增加一个随机值,使过期时间均匀分布;
3.2 无底洞问题
当缓存数据量非常大,Redis 集群需要分布部署到许多个节点上,要将数据使用哈希函数计算出 key,映射到这些节点上。相比于单机批量操作只需要一次网络操作,分布式集群的批量操作则需要涉及多次网络操作,使得缓存的整体性能变差。在这种情况下,更多的节点不代表更高的性能。
对于批量操作的解决方案有:
- 串行命令:对每个 key 逐个执行命令,时间复杂度最高;
- 串行 IO:使用 Redis Cluster 相同的方式,将所有 key 通过 CRC16 算法计算出散列值,再计算出 slot 值,再根据对应关系计算出节点,将属于同一个节点的 key 进行归类,然后对每个节点对应 key 集合依次执行批量操作;
- 并行 IO:同样计算出所有 key 所属节点并归类,对每个节点对应 key 集合并行执行批量操作;
- hash_tag:Redis Cluster 的功能,可以将多个 key 强制分配到一个节点上,只需要一次访问该节点即可完成批量操作,该方式维护成本较高且容易出现数据倾斜;
4. 不适合的场景
有很多场景是不适合使用 Redis 做缓存的。
强一致性
对数据一致性要求极高、或是要求操作原子性的场景不适合使用缓存,如金融系统和电商系统的交易金额、库存数量等,读取到的数据必须是最新的无延迟的。Redis 和数据库之间存在缓存更新的延迟,Redis 本身也存在主从同步的延迟,有可能在有时候存在数据的不一致性。
这种场景建议直接读写数据库,或是使用支持强一致性协议的分布式数据库。
数据不能丢失
虽然 Redis 提供了持久化的功能,但是不是完全可靠的,极端情况下可能会存在少量数据的丢失。因此不能将 Redis 作为唯一的数据副本。
Redis 只是作为缓存的数据副本,数据应该写入数据库。
写多读少
数据的写入和更新比较多,但读取次数相对少时,使用缓存的价值相对较低。每次数据变更除了更新数据库,还要额外更新或删除缓存,增加了额外开销和系统复杂性。
建议直接写入数据库或消息队列。
数据量巨大
当数据量远超内存,达到 TB 或 PB 级别,超过了单实例的内存容量,虽然可以通过部署 Redis 集群来解决,但是成本较为高昂。如果限制了 Redis 的内存占用,数据量过大可能会导致缓存命中率过低,失去了缓存的意义。
建议选择用磁盘存储或其他分布式缓存系统。
value 非常大
如果 value 是一个非常大的值如文件,不适合使用缓存,即占用网络连接和传输资源,也会阻塞其他小数据的请求。
建议使用对象存储或 CDN 来存储大文件,只在数据库保存访问地址。
复杂查询
Redis 只支持通过 key 来获取 value,不支持范围查询、聚合等复杂查询场景。
建议使用关系型数据库和搜索引擎来实现复杂查询的需求。