1. 缓存
Redis 最被我们熟知和常用的场景,是作为底层数据库的缓存层,通过将热点数据保存在缓存层,能加快读写性能,同时减轻底层数据库的读写负载。
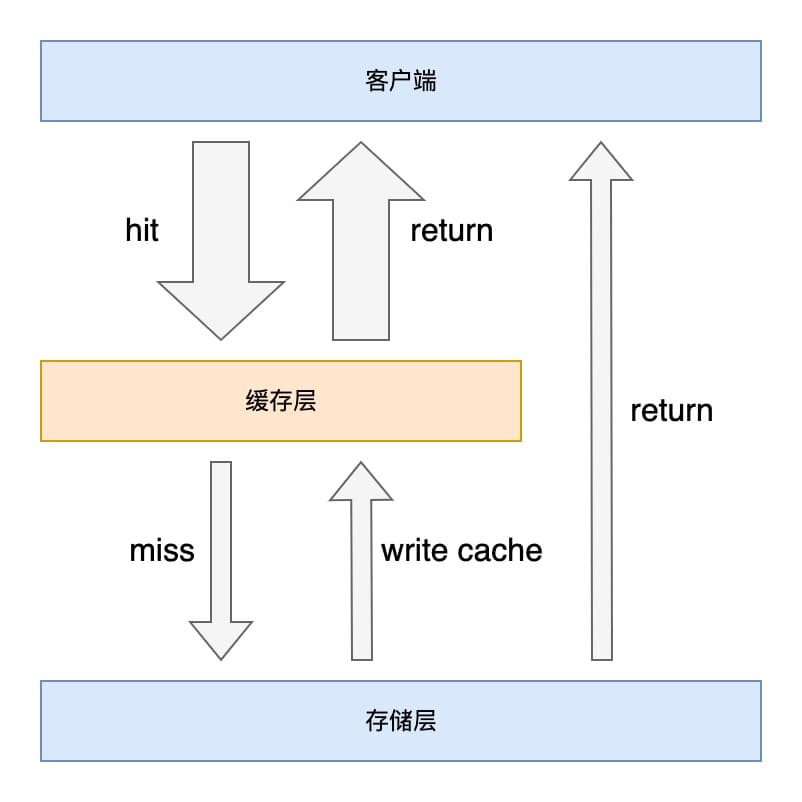
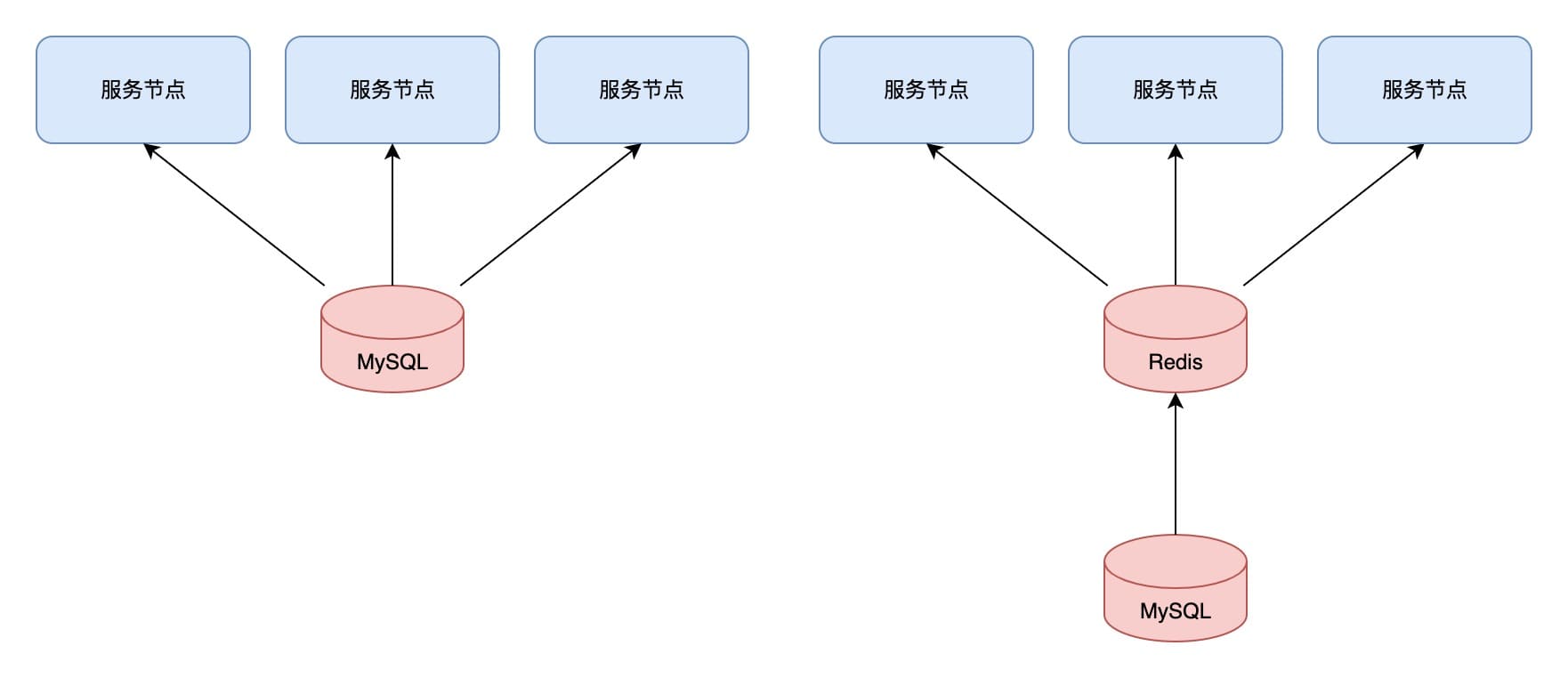
在以下场景,数据库中存在一部分读多写少的数据,我们的服务存在多个节点,每个节点定时将这部分数据读取到服务节点的内存中,当需要读取这部分数据时直接从内存读取。随着业务的发展,这部分数据满满变大,服务的节点数量也在增多,定时将数据读到每个节点内存的操作逐渐给底层数据库带来了明显压力。
调整为将这部分数据定时写入 Redis 缓存,各个节点从 Redis 读取,降低了底层数据库的压力。
Redis 提供了多种数据结构,每种数据结构适合于不同场景的缓存:
- 字符串:数字、文本数据,对象缓存,计数器,限流,分布式锁,共享session;
- 哈希:用户信息,购物车;
- 列表:消息队列,消息列表,文章评论列表;
- 集合:标签系统,社交网络好友关系,唯一访客统计,点赞统计;
- 有序集合:排行榜系统,延迟队列;
- bitmaps:大量用户的状态;
- hyperloglog:UV统计(允许一定的精度损失);
- geo:地理位置,附近地点搜索;
2. 分布式锁
分布式锁利用 Redis 原子操作的特性,实现了分布式系统的同步机制,以在分布式环境中协调多个节点或服务对共享资源的互斥访问。
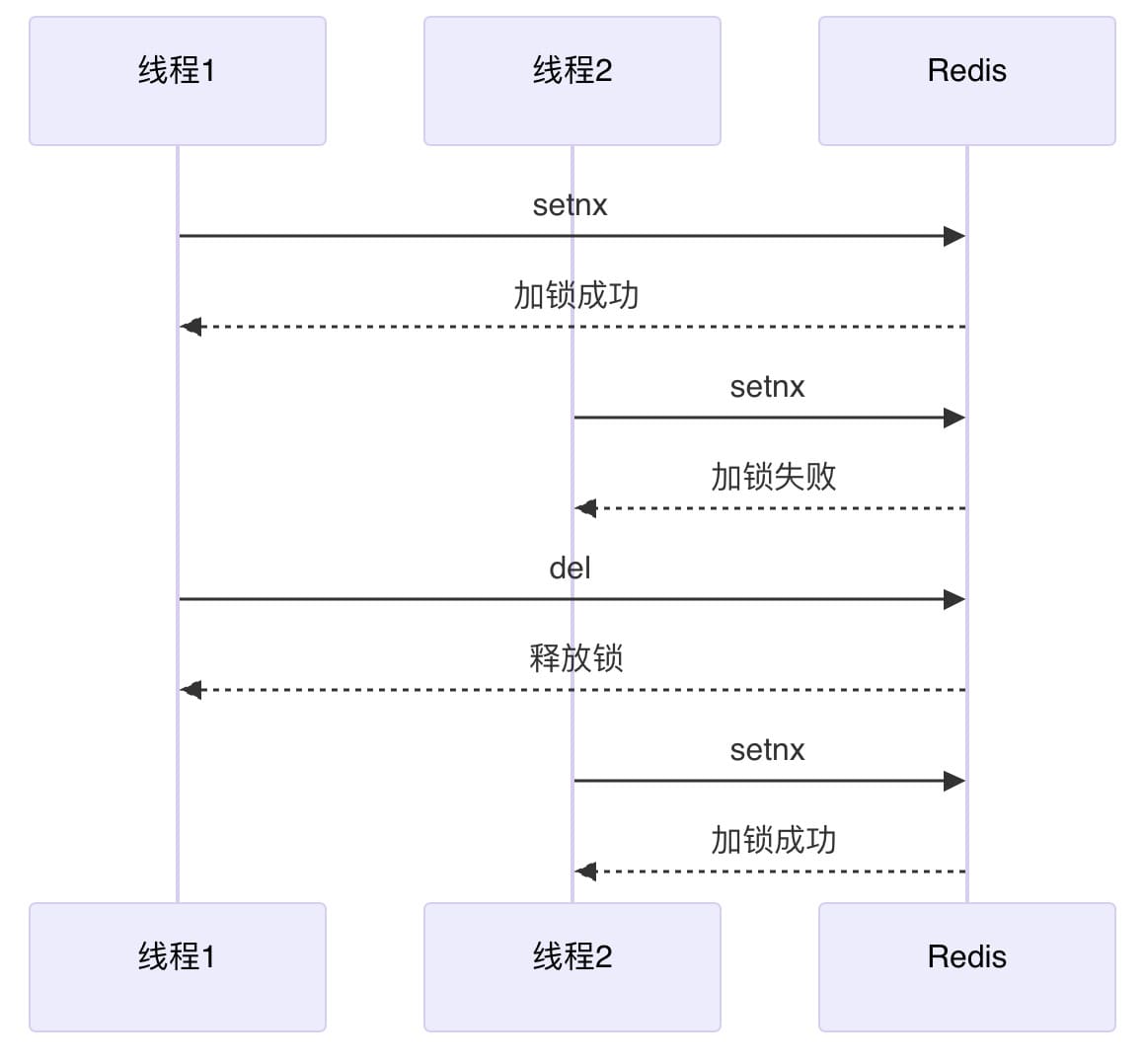
通过 setnx 命令设置一个 key,值为生成的唯一值,并带上过期时间,以在一定时间后自动释放锁,如果设置成功则表示加锁成功。加锁后,其他线程的 setnx 命令将会失败,也就是获取锁失败。为了避免锁被非加锁的客户端释放,每个客户端加锁和解锁时,可以设置一个唯一的标识值,可以是随机生成的 uuid 或者是进程 id。
当获取锁的线程处理完后,通过 del 命令删除该 key,表示释放锁,但需要先判断 key 对应的值是否为该客户端的标识值,这一过程通过 Lua 脚本保证原子性,该锁可以重新被其他线程所获取。
可重入锁
可重入锁(Reentrant Lock)是指分布式锁支持同一线程在持有锁的情况下再次请求加锁。
可重入锁需要维护一个计数器,记录锁被获取的次数,每次加锁将计数器加一,每次解锁将计数器减一,只有释放次数达到获取次数才能真正释放锁。另外每个线程需要通过一个唯一标识作为锁的值,标识锁的持有者,在加锁和释放锁时进行判断。通过 Lua 脚本来保证加锁和解锁的原子性。
Redisson 已经提供了可重入锁的实现。
Redlock 算法
Redlock 算法用于解决 Redis 分布式锁的单点故障问题,提高可用性,但是会令性能下降。
客户端尝试在多个独立的 Redis 节点使用 set 命令获取锁,建议使用奇数个节点,若超过一半节点成功获取锁,且时间小于锁的有效时间,则表示成功获取锁。执行完临界区代码后,客户端在所有获取了锁的节点释放锁。
看门狗机制
为了防止业务执行时间超过锁的过期时间,客户端可以在获取锁后启动一个看门狗线程,定期对锁进行续期。
3. 分布式限流
分布式限流是指在多台服务器之间,通过协作控制请求流量的过程,每个节点共享一个请求速率和计数器,使整体的流量控制在一个限制之内。
Redis 用于分布式限流,因为它的数据是内存操作,高并发场景下支持处理较高的 QPS。此外 Redis 还提供了 INCR、DECR 等原子操作和支持 Lua 脚本。
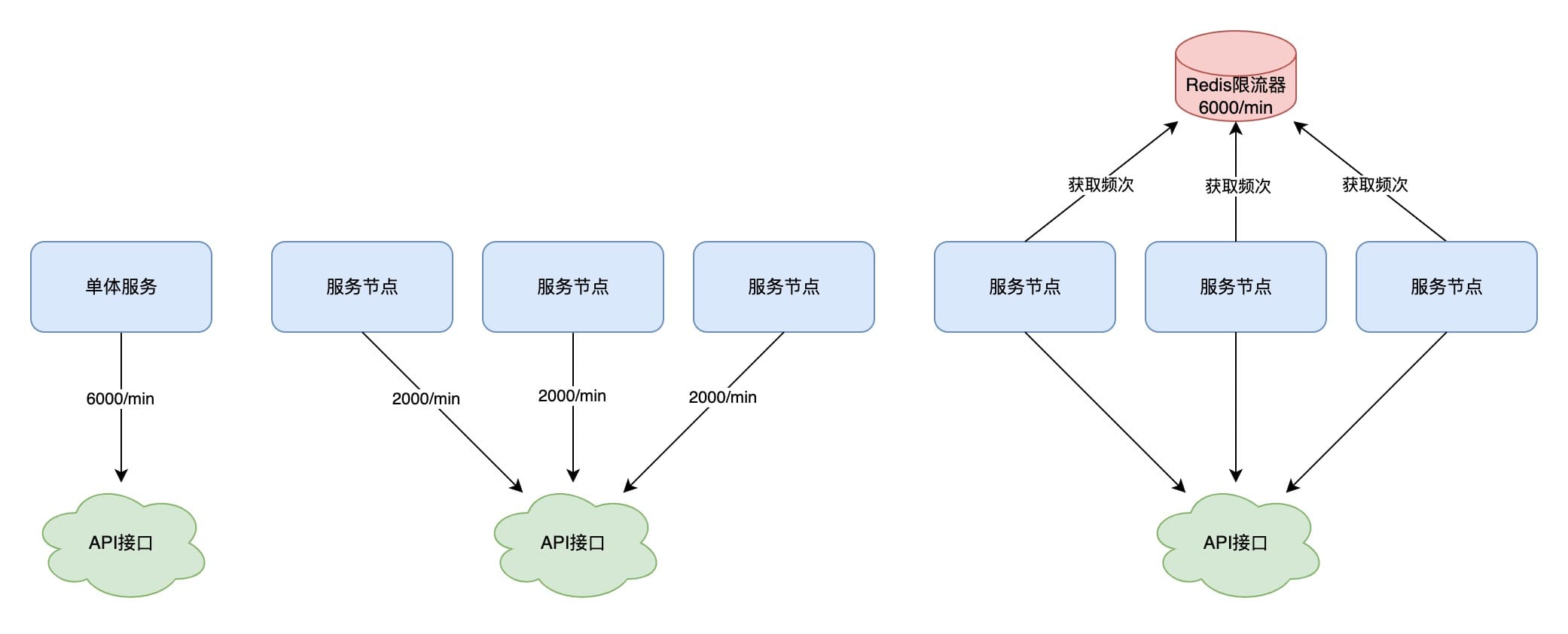
在以下场景中,我们的服务需要调用一个外部系统的 API 接口,该 API 接口对于调用有一定的调用频率限制,超出调用次数限制后会返回失败,因此我们的服务中需要控制调用频率。
假设该 API 接口调用频次限制是 6000 次每分钟,当我们的服务是单点服务时,可以在配置文件里将频次配置为 6000。当服务增加到 3 个节点时,需要手动将配置文件的频次改为 2000,当服务再增加到 6 个时,则需要再手动改为 1000。每次加减节点需要频繁手动调整配置文件,且当部份节点因为网络或其他原因没有用满平均频次的话,这部分频次无法供其他节点所用,相当于浪费掉了。
因此可以通过引入 Redis 作为分布式的限流器,节点在发起请求之前先向 Redis 获取调用请求,Redis 根据频次计数选择接受或拒绝请求,成功获取即可发起 API 接口调用。但是需要注意的是,当发现 Redis 不可用时,应当降级为本地限流,保证系统的可用性。
基于 Redis 实现的限流算法:
- 固定窗口算法:维护一个请求数计数器,请求到来时使用 INCR 计数加一,超过阈值则拒绝,设置过期时间,过期后自动删除进入下个时间窗口。Go 的 ulule/limiter 库使用该算法;
- 滑动窗口算法:使用有序集合存储请求的时间戳,每次请求移除过期时间戳,统计剩余元素数量,超过阈值则拒绝;
- 令牌桶算法:使用哈希或列表来存储令牌桶的令牌数和最后更新时间,请求时统计剩余令牌数量,令牌数为 0 则拒绝;
4. 消息队列
Redis 可以用来实现消息队列,即生产者将消息插入消息队列,消费者再从中取出消息进行消费,实现消息生产和消费的解耦。

列表
使用 Redis 中的列表(list)实现简单的消息队列功能,list 的实现数据结构为双向链表,可以很方便地在左右端插入或移除元素。
通过 rpush 配合 lpop,或者 rpush 加 blpop 来简单实现消息队列,它们的区别在于是否阻塞弹出元素。非阻塞用法一般使用轮询或者其他通知方式触发,适用于需要将数据批量取出处理的场景,而阻塞用法实时性更高,适用于消息需要尽快处理或同时监听多个队列的场景。
它的优点是实现简单、性能高,适用于轻量级队列,基于 Redis 持久化机制保证一定的数据安全性。但只支持单消费者,缺少消息确认、重试等机制,无法避免消息丢失。
在相册套间中,使用了列表作为消息队列。索引服务将文件变更通知相册服务时,使用的是 rpush+blpop 的组合,通过阻塞弹出能够更加及时地处理消息。相册内索引事件的批量和处理、进行智能模型识别的图片筛选和提交,则用了 rpush+lpop 的组合,通过另外的定时器触发消息消费,以实现延迟触发消费、批量提交识别的功能。
发布订阅(pub/sub)
生产者通过 PUBLISH 命令向频道发送消息,消费者通过 SUBSCRIBE 命令订阅服务,或者通过 PSUBSCRIBE 指定模型进行订阅。基于发布订阅模型,消息会广播给所有订阅者。
他的优点是实时性强,支持多消费者订阅,适用于广播式消息传递。但它不支持消息持久化,消息堆积超出上限会导致数据丢失,不支持消息确认、重试等机制。
stream
Redis 5.0 引入的新数据类型,通过 XADD 添加消息,XREAD 读取消息。支持消费者组实时消息分流。
stream 还支持消息确认机制、消息回溯、消费者组、历史消息查询等特性。
它的优点是支持消息持久化,支持消费者组,支持消息确认和回溯功能。但实现和内存占用高于列表,不如专业的消息队列如 Kafka 功能丰富。
虽然 stream 支持持久化,但 Redis 中 AOF 持久化写盘、主从切换时还是有可能存在存在少量数据丢失的可能,所以不能保证 stream 完全不丢消息。
相比于 Kafka,stream 使用内存存储消息,并可以配置持久化,性能更高,但是面对消息积压会导致内存资源紧张。而 Kafka 基于磁盘存储,可靠性更高,其他功能和管理工具更加丰富,对于消息积压的压力也没那么大。如果业务场景对于数据丢失比较敏感,写入量非常大,可能会产生消息积压,还是建议使用专业的消息队列。
对比
以上三种方式存在一些差异,需要根据实际场景来选择。
| 特性 | 列表 | 发布订阅 | stream |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 消费者 | 单消费者 | 多消费者(广播) | 多消费者(分流或广播) |
| 消息推送方式 | 客户端拉取 | 服务端推送 | 阻塞监听时服务端推送,非阻塞监听时客户端拉取 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
| 消费者组 | 不支持 | 不支持 | 支持 |
| 历史消息查询 | 不支持 | 不支持 | 支持 |
| 消息堆积 | 内存限制 | 有上限,超出丢失 | 内存限制 |