1. 简介
TDSQL(Tencent Distributed SQL)是腾讯打造的一款企业级数据库产品,这里主要介绍 TDSQL MySQL版(TDSQL for MySQL),它是部署在腾讯云上的一种支持自动水平拆分、Shared Nothing 架构的分布式数据库,针对 OLTP 场景设计,适用于高并发的联机访问。默认部署主备架构,提供容灾、备份、恢复、监控、迁移等全套解决方案。
根据腾讯云官方文档的介绍,TDSQL 单分片最大支持 6TB 存储,最大支持 24 万 QPS,实例性能可以随分片数量增加线性扩展。
2. 概念与语法
作为分布式数据库,TDSQL 将数据拆分并存储至多个节点上。节点(set、分片)是基于 MySQL 数据库主从协议联结成的一个组,是分布式实例中的最小数据单元。每个 set 内部都具有一主 N 备的高可用架构,而一个分布式实例是由 N 个 set 组成的,每个 set 存放不同范围的数据。
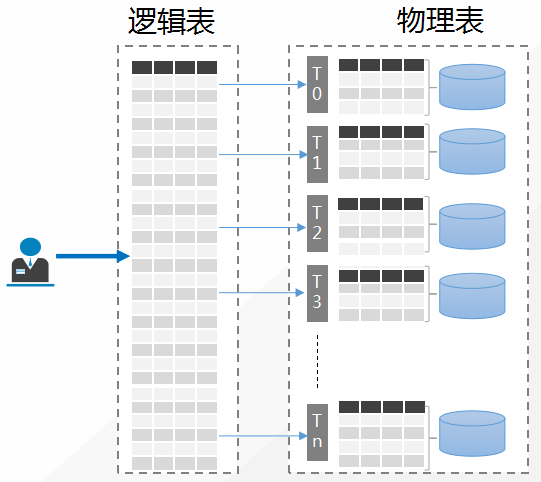
实例根据是否分片,分为集中式实例(no_shard),所以数据都在一个 set 上,和分布式实例(group_shard、shard),数据分布在 n 个 set 上。
表根据分片与否分为三类:
- 单片表(noshard 表),表数据全量存储在第一个 set 种,用于存储一些无需分片的表;
- 广播表,该表的所有操作都将广播到所有 set 种,每个 set 都有该表的全量数据,常用于业务系统的配置表;
- 分片表(shard 表、水平拆分表、一级分区表),分表需指定一个字段作为分片键,使用不同分片算法将数据分布到不同的 set 当中。range 和 list 容易导致严重的数据倾斜,推荐使用 hash 进行分表,通常使用主键 id 或日期等区分度高的列为分区键;
当处理大数据量读请求的压力大、要求高时,可以通过读写分离功能将读的压力分布到各个从节点上,实现读写分离。读写分离的基本原理是让主节点(master)处理事务性操作如增删改操作,让从节点(slave)处理查询操作,从而将读写分开处理,降低主节点的处理压力。
2.1 DDL语句
单片表创建时无需指定 shardkey,语法和 MySQL 完全一样,将全量数据存放早第一个节点。常用于数据量少,或不需要 join 分片表且更新量大的场景。过多单片表会导致第一个 set 的负载太大,考虑改为分片表。
create table noshard_table (a int, b int key);
广播表使用 shardkey=noshardkey_allset 创建。广播表会在每个节点写入全量数据,所有操作都将广播到所有节点上。主要用于提升和分片表进行跨节点的 join 操作的性能,常用于数据量少或更新少的场景,如配置表。
create table global_table_a
(
a int,
b int key
) shardkey=noshardkey_allset;
一级分区表有 hash、range、list 三种规则。
创建一级 hash 分区使用 shardkey 关键字指定拆分键,必须是主键一级所有唯一索引的一部分。
create table test1
(
a int,
b int,
c char(20),
primary key (a,b),
unique key u_1(a,c)
) shardkey=a;
创建一级 range 分区使用 tdsql_distributed by 指定拆分键,按范围划分分区。
create table t1
(
a int key,
b int
) tdsql_distributed by range(a) (s1 values less than(100), s2 val ues less than(200));
创建一级 list 分区同样是使用 tdsql_distributed by 指定拆分键,按列举值划分分区。
create table t2
(
a int key,
b int
) tdsql_distributed by list(a) (s1 values in(1,2), s2 values in (3,4 ));
二级分区表是将特定条件的数据进行分区处理,支持 range 和 list 两种格式的二级分区,语法和 MySQL 分区语法类似。日期和整型字段支持 year、month、day 函数。
CREATE TABLE employees_int
(
id INT key NOT NULL,
name VARCHAR(30),
hired date,
separated DATE NOT NULL DEFAULT '9999-12-31'
) shardkey=id
PARTITION BY RANGE ( year(hired) ) (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001)
);
CREATE TABLE customers_1
(
first_name VARCHAR(25) key,
last_name VARCHAR(25),
street_1 VARCHAR(30),
street_2 VARCHAR(30),
city VARCHAR(15),
renewal DATE
) shardkey=first_name
PARTITION BY LIST (city) (
PARTITION pRegion_1 VALUES IN('Beijing', 'Tianjin', 'Shanghai'),
PARTITION pRegion_2 VALUES IN('Chongqing', 'Wulumuqi', 'Dalian'),
PARTITION pRegion_3 VALUES IN('Suzhou', 'Hangzhou', 'Xiamen'),
PARTITION pRegion_4 VALUES IN('Shenzhen', 'Guangzhou', 'Chengdu')
);
支持新增和删除二级分区。
alter table customers_1 add partition (partition pRegion_5 VALUES IN('Wuhan', 'Nanjing', 'Guiyang'));
alter table customers_1 drop partition pRegion_1;
业务应尽量使用一级分区表,二级分区表适用于表结构不需变更而需要定期清理分区数据的场景,如日志流水表。
不要更改表中数据 shardkey 字段的值,也不要对 shardkey 字段改名或缩短字段长度至实际长度以下。
2.2 DML语句
对于分片表,proxy 会根据 shardkey 字段的值,将 SQL 指令请求路由至对应的数据库节点进行处理。当无法路由到特定节点时,SQL 指令将发送到集群的所有节点,在对数据库返回结果进行聚合和计算,影响执行效率。
查询数据应该尽量包含 shardkey 字段,这样就可以根据条件只路由到所需的节点。插入操作字段必须包含 shardkey,否则将会无法执行 SQL。更新和删除命令必须带 where 条件,否则也无法执行。
join 表时如果两个分片表的分表键相等,这部分数据会存储到同一个节点,此时相当于单机 join,数据处理效率更高。分片表和广播表也相当于单机 join。
一些查询涉及跨节点的数据交互,会拉取数据本地缓存以及网络数据传输,将使性能变差:
- 包含子查询
- 带有 having 条件
- 进行多个排序、分组、去重,如 count(distinct id)
- 多表 join 且分区字段不相等,或是单表 join 分区表
2.3 注释透传
注释透传指支持透传 SQL 语句到对应的一个或者多个物理分片,proxy 进行解析并将 SQL 语句透传到指定分片中。
# 指定所有分片
/*sets:allsets */
# 指定某一分片
/*sets:set_1*/
# 指定多个分片
/*sets:set_1,set_2*/
# shardkey 对应分片
/*shardkey:value*/
这里的每个分片都有名字,可以在网页控制台查看分片名字,也可以通过命令查询。
# 查看分片的名字
/*proxy*/show status
只有在必要的情况下才建议使用透传功能进行增删改操作,如之前的多分片操作失败导致部分分片执行未成功。透传 SQL 语句进行写操作时,因 proxy 不解析 SQL 语句,多个节点透传写操作将不使用分布式事务,可能导致数据不一致,此时建议分一个个节点进行操作。
3. 规范建议
3.1 读写分离
TDSQL 支持以下 4 种读写分离操作:
- 创建只读账号,系统将根据只读策略将读请求发往从机
- 配置 proxy 参数,通过解析语法过滤出读请求,默认把读请求发往备机
- slave 注释,在 SQL 中添加
/*slave*/标记后,将会被发送给备机 - 全局读写分离,自动将 SQL 中的读请求发向从机,且能识别事务、存储过程中的读语法并灵活处理,从机延迟较大时会造成性能下降
推荐使用只读账户或 slave 注释实现读写分离。
对主从延时敏感的查询语句建议直接从主库读取,对 CPU 负载影响较大的查询可以开启读写分离。
3.2 数据库设计规范
库:
- 默认存储引擎设置为 InnoDB
- 事务隔离级别使用 Read Committed
- 字符集使用 utf8mb4
- 保持同一个数据库的所有表、字段使用相同字符集
- 不同应用放到不同 db 中
- 库名称格式:业务系统名称_子系统名
表:
- 表必须有主键,且主键值禁止更新
- 显式指定存储引擎 engine=innodb
- 有表级别 comment
- 建表显式指定字符集 default charset=utf8mb4
- 活跃表中不建议使用 blob、text、varchar(>255) 等大字段
- 多个表中同一类型与含义字段使用相同的类型与属性
- 不使用外键做数据一致性保证,从业务上控制
列:
- 添加列级别 comment
- 添加字段 NOT NULL 属性,业务可以根据需要定义 DEFAULT 值
- 不在数据库中存储图片
- varchar 长度尽量小于 100,活跃表中不要使用 varchar(>255) 等大字段
索引:
- 索引名称添加前缀,主键使用
pk_,唯一键使用uniq_,普通索引使用idx - 创建索引多考虑建立联合索引,把区分度最高的字段放在前面
- 去除冗余索引,如一个索引字段是另一个索引字段的前面一部分则为冗余索引
DML 语句:
- select 语句指定字段名称,不使用 select *,减少 IO 和网络开销
- insert 语句指定字段名称,防止表字段更新后造成的错误
- DML 语句要有 where 条件,减少查询匹配范围
- where 条件比较字段类型必须一致
- where 条件不要只使用模糊匹配,要有等值或范围查询
- 批量更新插入使用批量进行,控制批量的大小
- 减少使用 or,使用多个条件查询进行 union
- 使用 covering index 提高性能,即索引的字段包含所有要查询的字段
表连接:
- 使用 join 代替子查询
- 多表 join 最好不要超过 3 个表
- 选取条件过滤后结果集较小的表作为驱动表
- join 字段匹配要命中索引
- group by 和 order by 子句只参考驱动表的列
排序分组:
- order by、group by、distinct 建议放到程序端去做,比较耗费数据库 CPU 资源
- 查询语句 where 条件过滤的结果最好保持 1000 行以内,否则 IO/CPU 过高
3.3 删除大表
生产环境删除大表,直接 drop table 可能会导致 TDSQL 实例挂起。
业务按时间清理数据,如按年度、月度清理,可以使用二级分区,在业务低峰期通过删除分区来清理数据。否则在业务低峰期,以小事务批量删除,每次 delete 操作限制 5000 行以内。