1. 简介
![]()
Neo4j 是一款高性能的图数据库,使用 Java 语言开发。它将结构化数据存储在网络(图)上而不是传统的表中,使用节点、关系、属性来存储和表示数据,这种数据模型使其能够处理高度互联、关系复杂的数据。
Neo4j 允许将数据库扩展到数十亿个节点,并且可以随时调整图的数据,并在大图中创建深度或广度搜索。
官方网站:https://neo4j.com/
源码地址:https://github.com/neo4j/neo4j
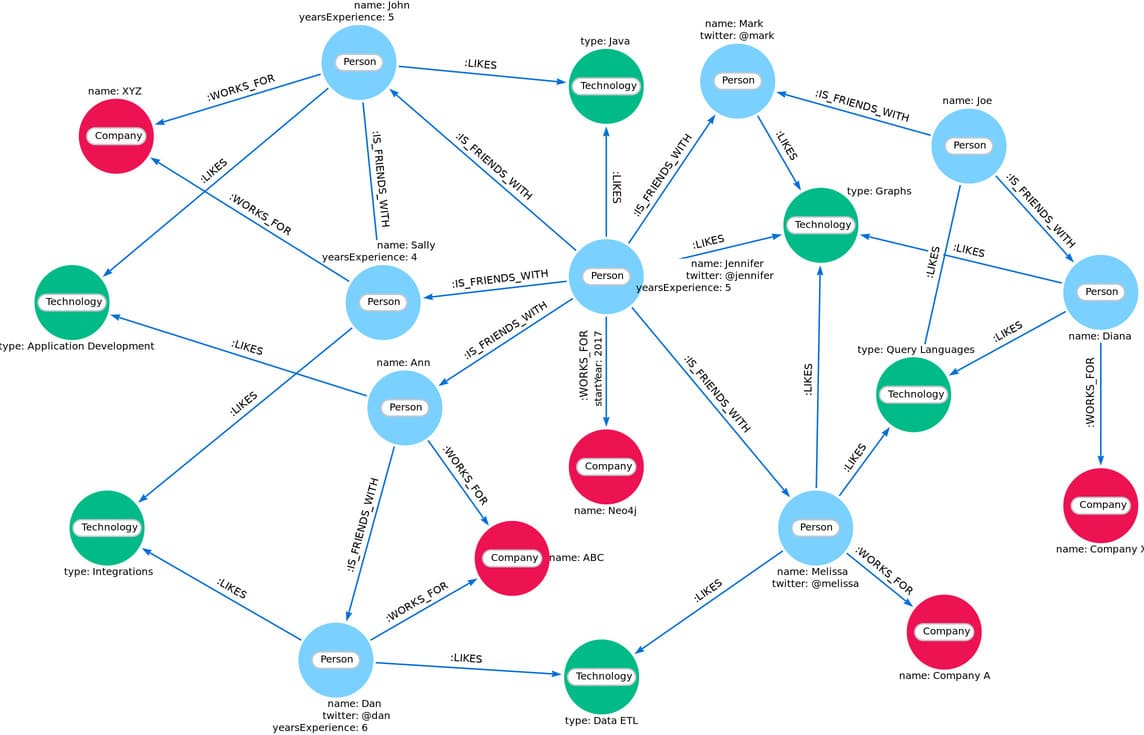
Neo4j 的技术特性:
- 以图的形式原生存储,而非通过关系表模拟,关系遍历速度比表连接操作更快;
- 无须预定义模式,可以随时添加新的节点、关系和属性;
- 使用 Cypher 查询语言来查询和操作图;
- 支持完整的 ACID 事务;
- 企业版支持分布式集群部署,提供高可用和水平扩展能力;
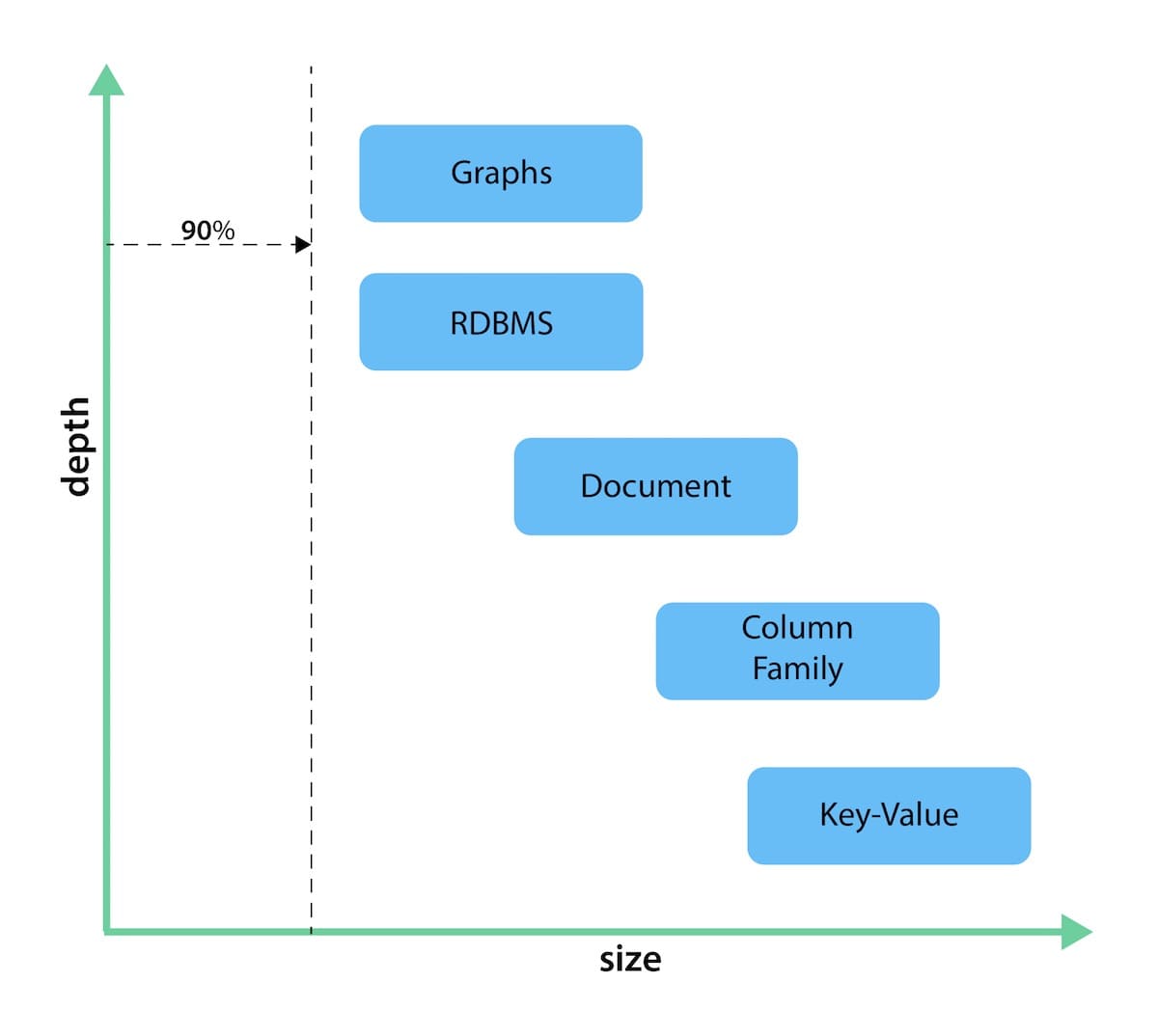
图数据库适合用来描述实体之间的关联关系,相比关系型数据库,它能够表达实体之间存在的多种类、更大数据深度的关联关系,同时保持最小的数据规模。
应用场景:
- 社交网络:分析用户关系,社区发现和影响力分析;
- 推荐系统:基于用户行为和物品属性的关系,提供个性化推荐;
- 欺诈检测:分析交易、账户、设备间的关联,识别欺诈和异常;
- 知识图谱:构建知识网络,用于智能问答和语义搜索;
不适合的场景:
- 不适合大规模、同质化数据集合的运算;
- 不适合对数据进行计数、求和、分组等操作;
- 不适合复杂的事务处理;
2. 概念
2.1 节点
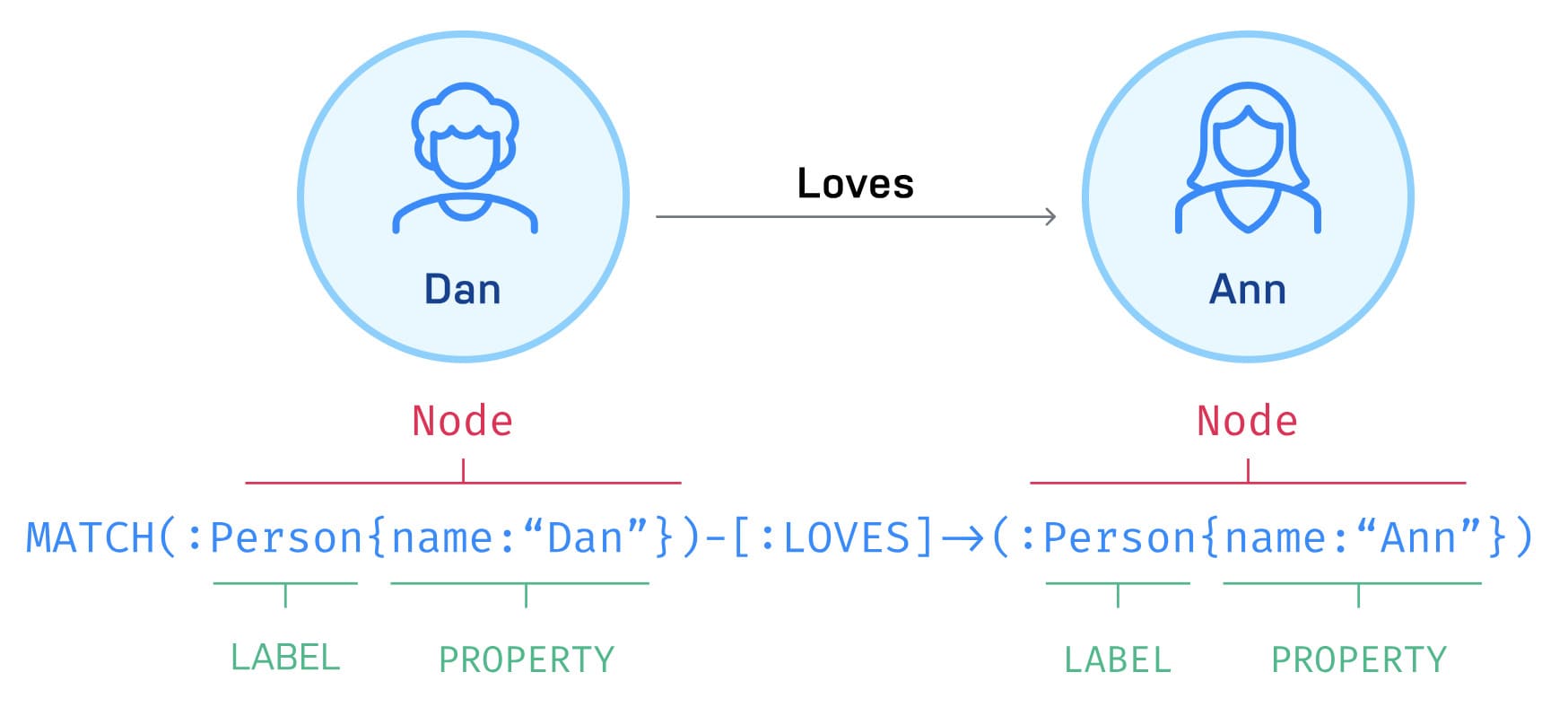
节点(Node)表示图中的实体。
节点有一个或多个标签(Label),表示它在图中的角色。节点的属性(Property)通过任意数量的键值对来表示。
CREATE (:Person:Actor {name: 'Tom Hanks', born: 1956})

2.2 关系
关系(Relationship)提供了两个节点之间的连接。
关系是有方向的,具有起始节点、结束节点和关系类型。关系必须具有单一的类型,并且可以有任意个属性。
CREATE ()-[:ACTED_IN {roles: ['Forrest'], performance: 5}]->()
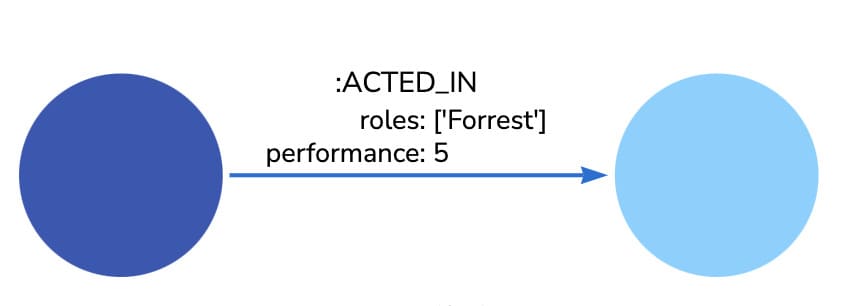
节点之间可以拥有不同类型的多个关系,而不会牺牲性能。
如下图是两个节点及其关系的示意图:
2.3 属性
属性(Property)是若干个键值对,可以用于节点和关系。
// 节点属性
CREATE (:Person:Actor {name: 'Tom Hanks', born: 1956})
// 关系属性
CREATE ()-[:ACTED_IN {roles: ['Forrest'], performance: 5}]->()
3. Cypher
Cypher 是 Neo4j 的声明式查询语言,也被称做 CQL。
Cypher 通过圆括号表示节点,通过箭头加方括号表示关系:
(:nodes)-[:relation]->(:otherNodes)
Cypher 包含以下数据类型:
- boolean:布尔值;
- byte:8 位整数;
- short:16 位整数;
- int:32 位整数;
- long:64 位整数;
- float:32 位浮点数;
- double:64 位浮点数;
- char:16 位字符;
- string:字符串;
3.1 概念
节点
节点通常用于表示数据模型中的名词或对象,节点用括号括起来表示,可以通过标签进行分组。
节点名称前有冒号表示一个类型,而没有冒号则表示一个变量。
// John 变量
(John)
// Person 类型,并且包含标签
(:Person{name:"John"})
节点可以绑定到变量中,以在后续子句引用匹配的数据实体。如下将标记为 Person 的节点绑定到变量 p,以在下文中引用:
MATCH (p:Person)
RETURN p
关系
关系可以存储节点之间的关联信息,表示为方括号和连接两个节点的箭头。
(Node1)-[]→(Node2)
关系名称前有冒号表示一个类型,而没有冒号则表示一个变量。
// LIKE 变量
(:Person)-[LIKE]→(:Technology)
// LIKE 类型
(:Person)-[:LIKE]→(:Technology)
关系总是有方向的,未指定方向的关系可以从两个方向遍历。
// 从左到右
(p:Person)-[:LIKES]->(t:Technology)
// 从右到左
(p:Person)<-[:LIKES]-(t:Technology)
// 未指定方向
MATCH (p:Person)-[:LIKES]-(t:Technology)
关系的类型类似于分组标签,一般是使用动词作为关系的类型,而节点则使用名次,可以很自然地表示现实中的关系。类型必须写在冒号后面,如果没有冒号就是变量。
// LIKES是类型
MATCH (p:Person)-[:LIKES]-(t:Technology)
// LIKES是变量
MATCH (p:Person)-[LIKES]-(t:Technology)
关系变量则用于在查询的稍后引用它。
// r是变量,LIKES是类型
MATCH (p:Person)-[r:LIKES]->(t:Technology)
RETURN p,r,t
属性
节点和关系中可以添加一到多个属性,以键值对的形式存在。
CREATE (p:Person {name:'Sally'})-[r:IS_FRIENDS_WITH]->(p:Person {name:'John'})
RETURN p, r
模式和语句
模式是用来声明关系的,需要通过 CREATE 子句将信息添加到数据库,然后通过 MATCH 来用模式检索数据。
// 模式
(p:Person {name: "Sally"})-[r:LIKES]->(t:Technology {type: "Graphs"})
// 插入
CREATE (p:Person {name: "Sally"})-[r:LIKES]->(t:Technology {type: "Graphs"})
// 检索
MATCH (p:Person {name: "Sally"})-[r:LIKES]->(t:Technology {type: "Graphs"})
RETURN p,r,t
3.2 语句
创建
CREATE 用于创建节点和关系。
// 创建节点
CREATE (p:Person)
// 创建节点,带有多种标签
CREATE (p:Person:Employee)
// 创建节点并带有属性
CREATE (p:Person{name:"John"})
// 创建关系
CREATE (p:Person {name:'Sally'})-[r:IS_FRIENDS_WITH]->(p:Person {name:'John'})
MERGE 先查询节点和关系是否存在,存在则返回,不存在则创建。
MERGE (p:Person{name:"John"})
SET 用于向节点和关系添加或设置属性。
// 添加属性
MATCH (p:Person{id:123})
SET p.age=30
查询
MATCH 用于查询节点和关系。
RETURN 用于返回查询的内容。
WHERE 用于过滤查询结果,通过比较运算符 =、<>、<、>、<=、>=、IS NULL、IS NOT NULL、IN、=~(正则表达式匹配)来比较结果,通过布尔运算符 AND、OR、NOT、XOR 来支持多个条件。
// 查询某种标签的节点
MATCH (p:Person)
RETURN p
// 查询并返回属性
MATCH (p:Person)
RETURN p.name,p.age
// 查询并指定条件
MATCH (p:Person)
WHERE p.name <> 'Tom' AND p.age < 30
RETURN p
// 查询并根据结果创建关系
MATCH (p1:Person),(p2.Person)
WHERE p1.id = 123 AND p2.id = 200
CREATE (p1)-[r:BORROW{date:"20260301",price:1000}]->(p2)
RETURN r
ORDER BY用于对查询结果进行排序,默认升序,可以添加 DESC 指定降序。
// 排序
MATCH (p:Person)
RETURN p.name,p.age
ORDER BY p.age
LIMIT 用于限制返回的行数。
SKIP 用于跳过返回的行数。
// 限制返回行数
MATCH (p:Person)
RETURN p
LIMIT 10
// 跳过返回行数
MATCH (p:Person)
RETURN p
SKIP 30
// 获取指定分页的行数
MATCH (p:Person)
RETURN p
SKIP 30 LIMIT 10
以上子句的顺序为 MATCH - WHERE - RETURN - ORDER BY - SKIP - LIMIT。
UNION 和 UNION ALL 将多个子句的结果合并为一组,前者去除重复行,后者保留重复行。
// 合并结果,去除重复
MATCH (p:Person) RETURN p.name,p.age
UNION
MATCH (e:Employee) RETURN e.name,e.age
// 合并结果,保留重复
MATCH (p:Person) RETURN p.name,p.age
UNION ALL
MATCH (e:Employee) RETURN e.name,e.age
删除
DELETE 用于删除节点和关系。
// 删除某一标签的节点
MATCH (p:Person)
DELETE p
// 删除关系
MATCH (p:Person)-[r]-(p:Person)
DELETE r
REMOVE 用于删除标签和属性。
// 删除属性
MATCH (p:Person)
REMOVE p.age
// 删除标签
MATCH (p:Person)
REMOVE p.Employee
3.3 函数
字符串函数
UPPER 函数将字符串转为大写字母。
MATCH (p:Person)
RETURN UPPER(p.name)
UPPER 函数将字符串转为小写字母。
MATCH (p:Person)
RETURN LOWER(p.name)
STARTS WITH 函数判断字符串前缀,ENDS WITH 函数判断字符串后缀,CONTAINS 函数判断字符串包含子串。
MATCH (p:Person)
WHERE p.name STARTS WITH "Com" OR p.name ENDS WITH "." OR p.name CONTAINS "-"
RETURN p.name
SUBSTRING 函数获取字符串的子串,需要指定开始和结束的索引下标。
MATCH (p:Person)
RETURN LOWER(p.name,0,10)
REPLACE 函数替换字符串的指定内容,指定搜索的子串和替换的内容。
MATCH (p:Person)
RETURN REPLACE(p.name,"old","new")
聚合函数
COUNT 函数返回行数。
MAX 函数返回最大值,MIN 函数返回最小值。
AVG 函数返回平均值,SUM 函数返回求和值。
MATCH (p:Person)
RETURN COUNT(*),MAX(p.age),MIN(p.age),AVG(p.salary),SUM(p.salary)
COLLECT 函数用于将聚合属性外的其他属性以列表列出。
SIZE 函数用于计算列表的大小。
MATCH (m:Movie)<-[:ACTED_IN]-(a:Person)
RETURN m.title AS movie, COLLECT(a.name) AS cast, SIZE(COLLECT(a.name)) AS cast_number, COUNT(*) AS actors
UNWIND 函数将指定列表分解为多个单独的值,用来匹配节点或关系的属性。
// 匹配节点
WITH [4, 5, 6, 7] AS experienceRange
UNWIND experienceRange AS number
MATCH (p:Person)
WHERE p.yearsExp = number
RETURN p.name, p.yearsExp
// 匹配关系
WITH ['Graphs','Query Languages'] AS techRequirements
UNWIND techRequirements AS technology
MATCH (p:Person)-[r:LIKES]-(t:Technology {type: technology})
RETURN t.type, collect(p.name) AS potentialCandidates
关系函数
STARTNODE 函数获取关系的开始节点,ENDNODE 函数获取关系的结束节点。
MATCH (a)-[movie:ACTION_MOVIES]->(b)
RETURN STARTNODE(movie),ENDNODE(movie)
ID 函数获取关系的 ID,TYPE 函数获取关系的类型。
MATCH (a)-[movie:ACTION_MOVIES]->(b)
RETURN ID(movie),TYPE(movie)
3.4 索引
为某类节点的特定属性创建索引,以加速查询。
CREATE INDEX ON :Person (name)
CREATE INDEX Person_name IF NOT EXISTS FOR (p:Person) ON p.name
删除已有索引。
DROP INDEX ON :Person (name)
3.5 约束
创建 UNIQUE 约束用来避免指定的属性产生相同的值。
CREATE CONSTRAINT ON (p:Person)
ASSERT p.name IS UNIQUE
删除已有约束。
DROP CONSTRAINT ON (p:Person)
ASSERT p.name IS UNIQUE