1. 索引
索引是数据库系统里面最重要的概念之一,索引的出现是为了提高数据查询的效率,相当于数据库的表的目录。
可以加速数据查询的数据结构中,哈希表适用于只有等值查询的场景,如 Redis 等 NoSQL 引擎,而有序数组适合进行等值查询和范围查询,但只适合静态数据的查询,数据插入删除更新的成本较大,它们都不适合关系型数据库的索引。结合业务场景,关系型数据库通常使用搜索树来实现索引。
树结构中最简单的是二叉树,每个节点最多有两个子节点,索引数据通常存在磁盘中,需要时再读入内存中,对于一个数据量达到百万级别的大表,树的高为 20,一次查询可能需要访问 20 个数据快,频繁读取磁盘会造成性能降低。
因此,可以使用多叉树来实现索引,每个叶子节点可以有更多的子节点,因此树的高就不会太大,避免了多次读取磁盘带来的性能损耗。InnoDB 的整数字段索引的 N 叉树中 N 大概是 1200,一棵树高为 4 时最大可以存 17 亿个值,树的根节点数据快总是保存在内存中的,因此一次查询最多只要访问 3 次磁盘,如果查询的值不在叶子节点或之前已经加载到内存,访问次数可以更少。
2. InnoDB 索引模型
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的,每一个索引在 InnoDB 里面对应一棵 B+ 树。
B+ 树对比 B 树的区别在于,B+ 树只有叶子节点储存完整数据,B 树的叶子节点和非叶子节点都储存数据。MySQL 选择 B+ 树,虽然它的查询性能不一定高于 B 树,但是更稳定,非叶子节点不存储数据使得单个节点能容纳更多键,降低树高和查询磁盘IO次数,也更适合磁盘存储和节点分裂合并操作。
B+ 树索引的每一个节点都是一个数据页,一个数据页默认占用 16KB 存储空间。
按叶子节点保存的内容,索引分为两类:
- 主键索引,又叫聚簇索引(clustered index),key 是表的主键,叶子节点保存整行数据;
- 非主键索引,又叫二级索引(secondary index),叶子节点保存主键的值;
主键索引的 B+ 树,叶子节点储存的是一行的完整数据。
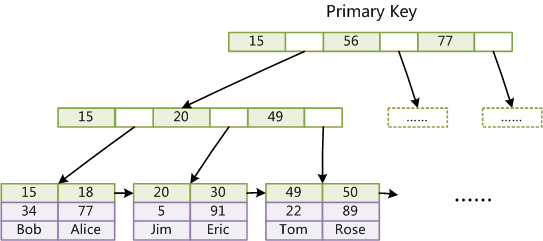
非主键索引的 B+ 树,叶子节点储存的是对应主键的值。
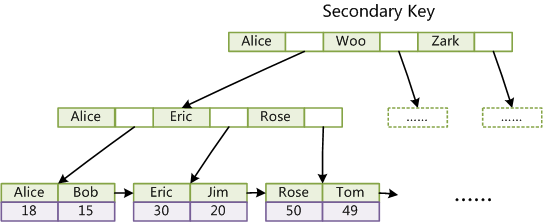
通过主键索引查询,只需要搜索这一个索引树,就可以获取数据行的所有数据。通过非主键索引,会先获得主键,然后再通过主键去主键索引查询,这个过程称为“回表”,相比会多一次查询。
建议使用一个自增的整型 ID 作为主键,这样在表插入新数据时,相当于给主键索引进行追加操作,不会涉及 B+ 树的节点分裂合并,写数据成本较低。且主键类型的长度越小,普通索引的叶子节点就越小,普通索引的空间占用也就越小。
ID int NOT NULL PRIMARY KEY AUTO_INCREMENT, # 主键
联合索引是由多个字段组成的索引。
唯一索引在对指定一或多列创建一个索引的同时,还会对列实施唯一性约束。主键索引也满足唯一性约束。
索引覆盖
当通过索引查询满足索引覆盖时,就不需要回表查询主键索引了。索引覆盖是指,本来通过一个非主键索引查处主键 ID,然后通过回表去查询那行数据,如果非主键索引本身已经包含了查询所需要的所有字段,或者只是查询某个字段在范围内的数据行数时,只查询非主键索引就可以获取所需信息,不需要通过回表查询主键索引。
最左前缀原则
索引查询遵循最左前缀原则,对于联合索引 (A, B, C),通过 ABC 或 AB 或 A 查询都能使用这个索引,但是通过 B 或 BC 查询就无法使用索引,需要再创建一个 (B, C) 的联合索引。利用该原理,在建表的时候可以考虑通过一个索引满足多种条件查询,减少维护多余索引。
索引下推
索引下推(index condition pushdown) 是指在通过一个索引查询时,先对索引中包含的字段过滤掉不满足条件的记录,然后再对未过滤的记录去主键索引进行回表查询,可以减少回表次数。
INCLUDE 索引
INCLUDE 索引在 MySQL 8.0 引入,允许索引中包含非索引键列,这些列不作为索引键,不影响索引层级结构,仅存储在叶子节点,用来在查询这些额外列时满足索引覆盖,而不用回表查询。
CREATE INDEX index_name
ON table_name (col1, col2, ...)
INCLUDE (col3, col4, ...);
3. MyISAM 索引模型
MyISAM 的索引和 InnoDB 不同,它的表数据和索引是分开的,表数据存储在 MYD 文件中,索引存储在 MYI 文件中。所有索引都是非聚簇索引,索引存储的是数据行的行号而非数据,也就是所有索引的查询都必须再去表数据查询一次。
MyISAM 在只读或读多写少的场景中速度更好,更有优势。