1. 简介
![]()
MySQL 是一款开源的关系型数据库管理系统(RDBMS),以高性能、可靠性、易用性和低成本著称。
MySQL 支持多种存储引擎:
- InnoDB 是默认引擎,支持事务、行级锁、外键约束、崩溃恢复能力,适用于高可靠性和并发控制场景;
- MyISAM 则提供更高的读性能,适用于读密集型操作,但不支持事务和行级锁;
- Memory 将数据保存在内存,不具备持久化能力,适用于临时表和缓存;
- Archive 用于存储大量的归档数据;
MySQL 支持单点、复制、集群等多种部署方式,支持运行在不同的操作系统。
MySQL 主要应用于 Web 应用、中小型网站、嵌入式系统等使用场景。
2. 基础架构
MySQL 属于客户端/服务器架构(C/S 架构),客户端向服务器发起请求,服务器负责响应客户端的请求、对存储的数据进行处理,服务器程序进程称为 MySQL 数据库实例(instance),可以同时处理多个客户端的连接和请求。
MySQL 服务器的基本架构主要分为 Server 层和存储引擎两部份。Server 层包括连接器、查询缓存、优化器、执行器等,涵盖核心服务功能如存储过程、触发器、视图、内置函数。存储引擎层负责数据的存储和提取,支持 InnoDB、MyISAM、MEMORY 等,默认存储引擎是 InnoDB。
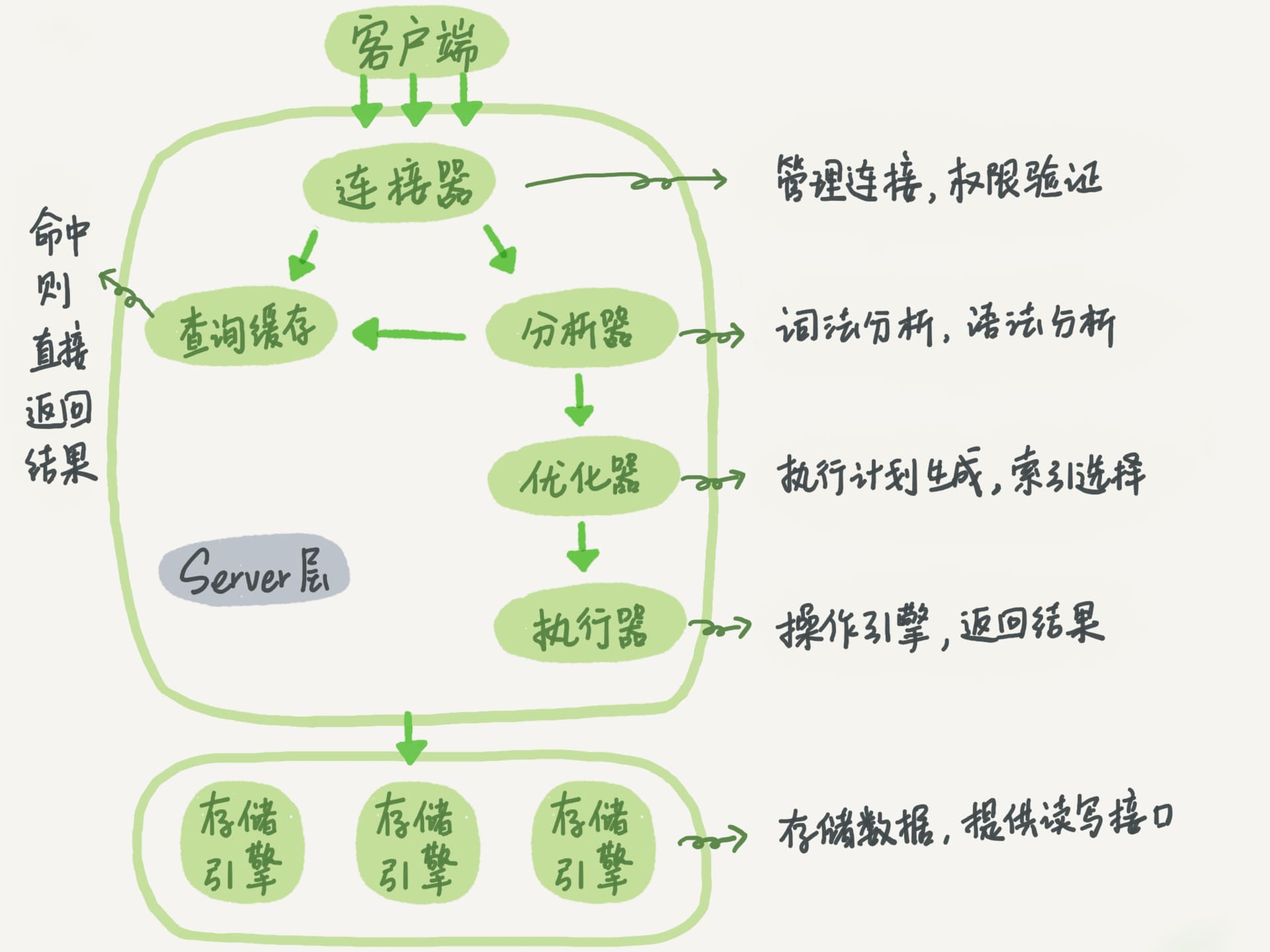
查询缓存很容易失效且命中率不高,不建议使用,在 MySQL 8.0 中已经删掉这块功能。
查看当前服务器支持的存储引擎:
show engines;
3. 存储引擎
MySQL 的主要存储引擎有 InnoDB、MyISAM 和 Memory 等。
在 5.5 版本之前默认存储引擎是 MyISAM,从 5.5 版本开始默认存储引擎换成了 InnoDB。
对它们的一个简单对比:
| 特性 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 事务支持 | 支持 | 不支持 | 不支持 |
| 锁 | 行级锁+表级锁 | 表级锁 | 表级锁 |
| 数据持久化 | 高,支持崩溃恢复 | 低,易损坏 | 无 |
| 外键 | 支持 | 不支持 | 不支持 |
| 性能 | 较稳定,适合大数据量 | 查询速度快,写入受限 | 极快,数据量受内存限制 |
| 适用场景 | 高并发写、事务控制、OLTP | 读多写少、全文索引 | 临时表、缓存 |
3.1 InnoDB
InnoDB 是 MySQL 从 5.5 版本开始至今的默认存储引擎。
InnoDB 完全支持 ACID 事务,包括回滚、崩溃恢复等,采用行级锁和 MVCC,适合高并发写入操作,支持外键约束,内置了 redo log 和 undo log,保证数据的持久性。
适用于 OLTP 应用如电商、支付等频繁读写数据的高并发场景,以及需要外键约束和事务控制的场合。
InnoDB 的架构设计包含内存架构(In-Memory Structures)和磁盘架构(On-Disk Structures)两大块。

3.1.1 Buffer Pool
Buffer Pool 是 InnoDB 存储引擎的核心内存组件,通过将表和索引数据从硬盘读取出来缓存在内存,减少磁盘 I/O 操作,提升数据库读写性能。
读写操作
当查询需要访问某数据页时,InnoDB 首先检查该页是否在 Buffer Pool 中,如果存在(缓存命中),则直接返回内存中的数据,不需要读取磁盘,如果不存在(缓存未命中),则从磁盘读取该页到 Buffer Pool 中再返回。
当发生数据插入、删除、更新时,直接修改 Buffer Pool 中的数据页,修改过的页称为脏页,由后台线程异步刷新到磁盘。这种延迟写入策略将多次随机磁盘写操作合并,以提升数据库的写入性能。
内部结构
Buffer Pool 内部以页(Page)为单位进行管理,缓存页对应硬盘中的数据页,默认大小为 16KB。每个缓存页对应一个控制块(Control Block),它存储缓存页的元数据如表空间号、页号、锁信心等。此外还有几个管理链表,free 链表管理空闲的缓冲页,flush 链表管理被修改待刷新到磁盘的脏页,LRU 链表用于在没有空闲缓冲页时淘汰缓冲页。
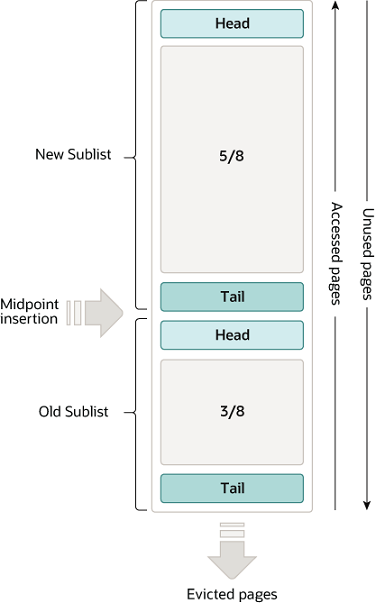
淘汰算法
Buffer Pool 使用 LRU(最近最少使用)算法的变种作为缓存淘汰策略,在缓存满时淘汰最近最少使用的部份页,来释放空间。
LRU 列表分为两个子列表,其中 5/8 的部份保存最近频繁访问的数据页,另外 3/8 部份保存访问频率较低的数据页。当 InnoDB 将数据页写入 Buffer Pool 时,如果是 SQL 发起的操作,将它插入新列表的头部,如果是 InnoDB 发起的预读操作,将它插入旧列表的头部。两个子列表中的页面随着数据插入逐渐向后移,并在移到旧列表尾部后被淘汰掉。
配置大小
Buffer Pool 的默认大小为 128MB,也可以通过配置 innodb_buffer_pool_size 来指定大小,尽可能调大可以提升 MySQL 的性能。对于专门用于运行 MySQL 的服务器,建议将其设置为总内存的 50% - 80%,但如果设置的过大导致开始使用 swap 内存,反而会降低性能。
[server]
innodb_buffer_pool_size = 268435456
Change Buffer
Change Buffer 是 Buffer Pool 的一部份,用于缓存当二级索引页不在 Buffer Pool 中时的写操作。
对于插入、删除、更新操作产生的缓冲更改,若目标页不在 Buffer Pool,将变更记录写入 Change Buffer 生成 Redo Log 以保证持久化,后续读取该索引页时,将 Change Buffer 中的变更合并到 Buffer Pool,触发异步刷盘。
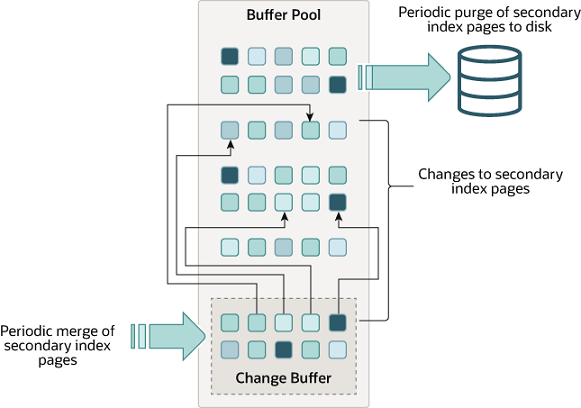
对二级索引的插入、删除、更新操作往往顺序较为随机,Change Buffer 可以避免从磁盘读取二级索引页至 Buffer Pool 产生的大量随机访问 I/O。
在磁盘上,Change Buffer 属于系统表空间的一部份,当服务器关闭时,索引变更将在此处缓冲存储。
Adaptive Hash Index
Adaptive Hash Index(AHI,自适应哈希索引)是 InnoDB 内部自动创建和管理的哈希索引,用于优化等值查询的性能。
它会将频繁访问的索引键映射到哈希表,无需使用 B+ 树的逐层查找,直接定位到目标数据页。当不再被频繁访问时会被从哈希表移除,重新通过 B+ 树查找数据页。
建议在以等值查询的 OLTP 使用场景中开启。
3.1.2 Log Buffer
Log Buffer 用于临时缓存重做日志(Redo Log)。
所有事务对数据的修改,对应的 Redo Log 会先写入 Log Buffer,然后按策略批量刷新到磁盘中的 Redo Log 文件中。
Log Buffer 能减少磁盘 I/O 次数,同时提升事务的响应速度。
3.1.3 Tablespace
Tablespace(表空间)是 InnoDB 逻辑结构的最高层,所有数据都存放在表空间中。
当配置了 innodb_file_per_table=ON(默认),则每张表的数据会单独放到一个独立表空间内。如果设置为 OFF 则会都放到系统表空间中,容易使文件变得非常大,不建议使用。
System Tablespace
System Tablespace(系统表空间)保存在一个名为 ibdata1 的文件,这里还保存了 Change Buffer 在磁盘上的数据、回滚信息、系统事务信息。
File-Per-Table Tablespace
File-Per-Table Tablespace(独立表空间)是默认的表空间类型,一个表对应磁盘上的一个 .ibd文件。
表空间分为多个 segment(段),有管理叶子节点的段和非叶子节点的段。segment 中包含了 extent(区),每个区是一组连续的 page(页),默认有 64 个页,大小为 1MB。每个 page(页)包含了多个 row(行),大小为 16KB。
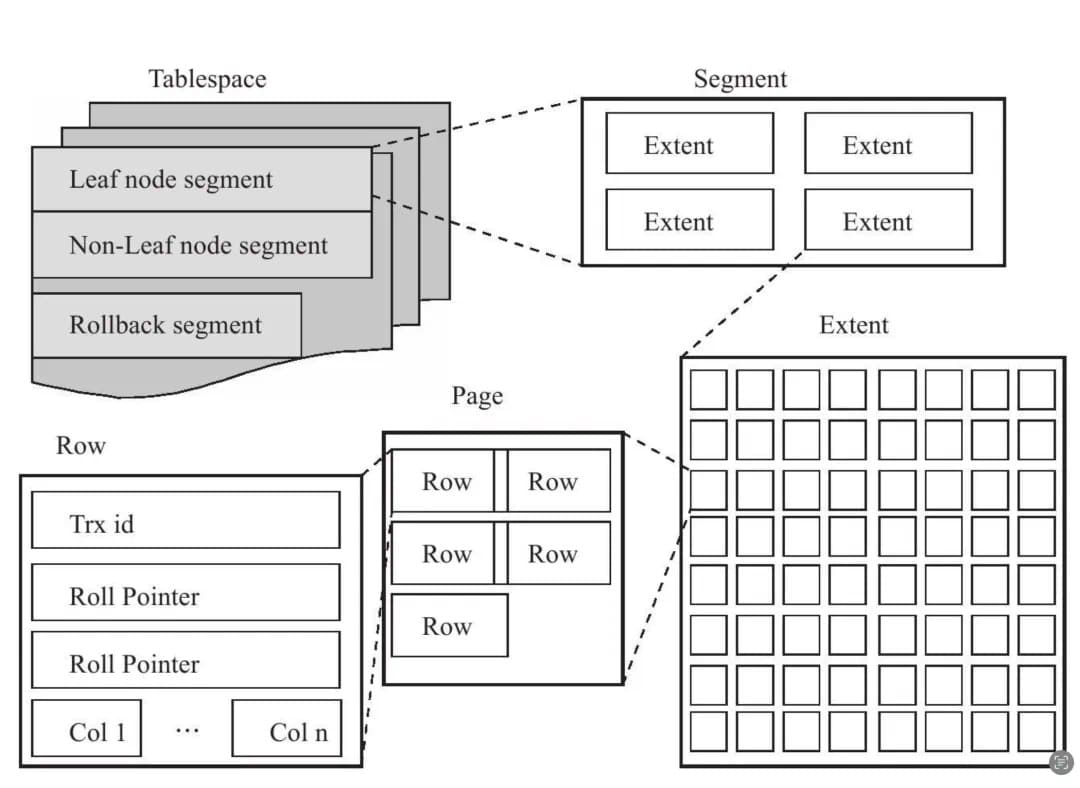
General Tablespace
General Tablespace(通用表空间)是一种共享表空间,能存储多张表的数据,通过 CREATE TABLESPACE 创建。
Undo Tablespace
Undo Tablespace(撤销表空间)用于管理事务回滚日志(Undo Log)。
Temporary Tablespace
Temporary Tablespace(临时表空间)存储创建的临时表和临时表的回滚段。
3.1.4 Double Write Buffer
InnoDB 的页大小为 16KB,而操作系统的页是 4KB 或 8KB,将一页数据刷到磁盘要写多页,并非原子操作,可能存在写了部份磁盘的页时发生断电。
InnoDB 会先把要刷到磁盘的页先写到内存中的 Double Write Buffer(双写缓冲),它包含内存和磁盘的部份,它会将内存中的部份同步到磁盘的部份。然后将一页数据写到磁盘中的多个页,如果发生崩溃,则从 Double Write Buffer 的磁盘部份取出进行崩溃恢复。
3.2 MyISAM
MyISAM 是 MySQL 在 5.5 版本之前的默认存储引擎。
MyISAM 不支持事务,没有崩溃恢复机制,采用表级锁,支持全文索引。
适用于只读或读多写少的场景,如数据仓库、日志存储、数据统计、报告生成等业务。
3.3 Memory
Memory 所有数据存储在内存中,不支持持久化,采用表级锁,采用固定长度行存储。
适用于临时表和缓存场合。️
4. 编码
4.1 字符集和比较规则
字符集用于表示二进制数据和字符串的映射关系。
MySQL 常用字符集有:
- ASCII:128 个字符,每个字符固定 1 字节;
- latin1(ISO 8859-1):256 个字符,适用于西欧语言,每个字符固定 1 字节;
- GB2312:包含中文、日文、俄文、希腊字母、拉丁字母等,兼容 ASCII,每个字符 1 或 2 个字节;
- GBK:对 GB2312 的扩充;
- utf8(utf8mb3):支持大部分 UTF-8 字符,每个字符 1 - 3 个字节;
- utf8mb4:支持完整的 UTF-8 字符,每个字符 1 - 4 个字节,建议使用该字符集而不是 utf;
比较规则规定了字符串比较是否区分大小写、是否区分重音、二进制方式比较等,每种字符集对应若干比较规则,可以从名称中对应,如 utf8_general_ci、gb2312_chinese_ci、utf8_bin 等。
字符集和比较规则分为服务器、数据库、表、列四个级别。
MySQL 服务器默认字符集是 utf8,默认比较规则是 utf8_general_ci,也可以通过配置修改,可以通过 show variable 查看。
[server]
character_set_server=gb2312
collation_server=gb2312_chinese_ci
其他各级字符集和比较规则的设置:
# 数据库级别
CREATE DATABASE <table> CHARACTER SET <charset> COLLATE <collation>;
ALTER DATABASE <table> CHARACTER SET <charset> COLLATE <collation>;
# 表级别
CREATE TABLE <table> CHARACTER SET <charset> COLLATE <collation>;
ALTER TABLE <table> CHARACTER SET <charset> COLLATE <collation>;
# 列级别
CREATE TABLE <table> (<row> <rowtype> CHARACTER SET <charset> COLLATE <collation>);
4.2 InnoDB 行格式
InnoDB 存储引擎支持多种行格式,它们在存储空间、空间效率、适用场景上不同。
REDUNDANT(冗余格式)是最早的原始行格式,存储效率较低。NULL 值也会占用固定空间。适用于早期版本兼容和较短 BLOB 字段场景。
COMPACT(紧凑格式)减少了部份存储空间,但 CPU 消耗略高。NULL 值使用二进制位标记,非 NULL 字段通过逆序排列,变长字段前 768 字节存本地,其余通过指针存在溢出页。包含事务 ID、回滚指针等隐藏列。适用于较多变长字段且平衡存储与查询性能的场景。
DYNAMIC(动态格式)优化了大字段处理,大字段如 VARCHAR、BLOB 完全存在溢出页,本地保留 20 字节指针,支持大索引。适用于大量长文本、二进制数据的场景。
COMPRESSED(压缩格式)基于 DYNAMIC 格式,增加了数据页压缩功能,减少了磁盘占用,但会增加 CPU 负载。适用于空间有限或海量数据的场景。
设置行格式:
CREATE TABLE <table> ROW_FORMAT=<row type>;
ALTER TABLE <table> ROW_FORMAT=<row type>;
MySQL 从 5.7 开始默认行格式为 DYNAMIC,到了 8.0 移除了 REDUNDANT 和 COMPACT 的支持。频繁更新的表适合用 DYNAMIC,数据量大且只读适合用 COMPRESSED。
5. 数据库
MySQL 会自动创建几个系统数据库,其中包含了 MySQL 服务器运行所需的信息和运行状态。
- mysql:存储 MySQL 的用户帐户和权限信息,运行过程的日志信息,帮助信息以及时区信息;
- information_schema:保存 MySQL 服务器维护的所有其他数据库的信息,如有什么表、什么视图、触发器、列、索引等元数据;
- performance_schema:MySQL 服务器运行过程的状态信息,统计最近执行的语句、每阶段话费的时间和内存使用情况;
- sys:通过视图把 information_schema 和 performance_schema 结合起来;
6. 执行计划
MySQL 通过查询执行计划来查看语句执行的具体方式,在语句前加上 EXPLAIN 关键字查看。虽然增删改查语句都能查看,但是主要还是用于 SELECT 语句上。
# 查询语句
select * from user where age = 10;
# 执行计划
explain select * from user where age = 10;
# JSON格式执行计划
explain format=json select * from user where age = 10;
输出的各列含义:
- table:表名;
- id:每个 SELECT 关键字分配的唯一 id,普通查询或连接查询只有一个 id,而子查询或 UNION 则会产生多个 id;
- select_type:表的类型;
- SIMPLE:单表查询;
- PRIMARY:对包含 UNION 或子查询的大查询中的第一个查询;
- UNION:UNION 查询中除了第一个查询;
- SUBQUERY:子查询,用于条件匹配中;
- DERIVED:派生表,用于作为查询 from 的对象;
- MATERIALIZED:优化器将子查询物化后进行连接查询;
- partitions:分区信息,表示分区表查询用到的分区,非分区表为 NULL;
- type:访问方法;
- system:表只有一条记录且存储引擎(如 MyISAM、MEMORY)的统计数据是精确的;
- const:根据主键或唯一索引与常数等值匹配;
- eq_ref:连接查询时,被驱动表是通过主键或非 NULL 唯一索引进行等值匹配;
- ref:通过普通二级索引与常量等值匹配,连接查询被驱动表通过普通二级索引与驱动表某列等值匹配;
- ref_or_null:对普通二级索引等值匹配且该列可以是 NULL;
- index:可以使用索引覆盖,但需要扫描全部索引记录;
- index_merge:查询匹配多个字段都各自有索引,对索引结果进行合并时;
- unique_subquery:IN 子查询语句,被转为 EXISTS 子查询,等值匹配使用主键或非 NULL 唯一索引时;
- index_subquery:IN 子查询语句,被转为 EXISTS 子查询,等值匹配使用普通二级索引时;
- range:使用索引匹配值的集合或范围区间;
- fulltext:全文索引;
- ALL:全表扫描;
- possible_key, key:查询时用的索引;
- key_len:索引列实际的最大字节数,如果可以为 NULL 则加一;
- ref:使用索引进行等值匹配时,和索引列匹配的类型;
- const:常数;
- func:函数;
- 列的名称;
- rows:预计扫描的索引记录行数;
- filtered:使用索引扫描区间获取到的记录数,再满足其他搜索条件后,预测记录数占前者的百分比;
- Extra:额外信息;
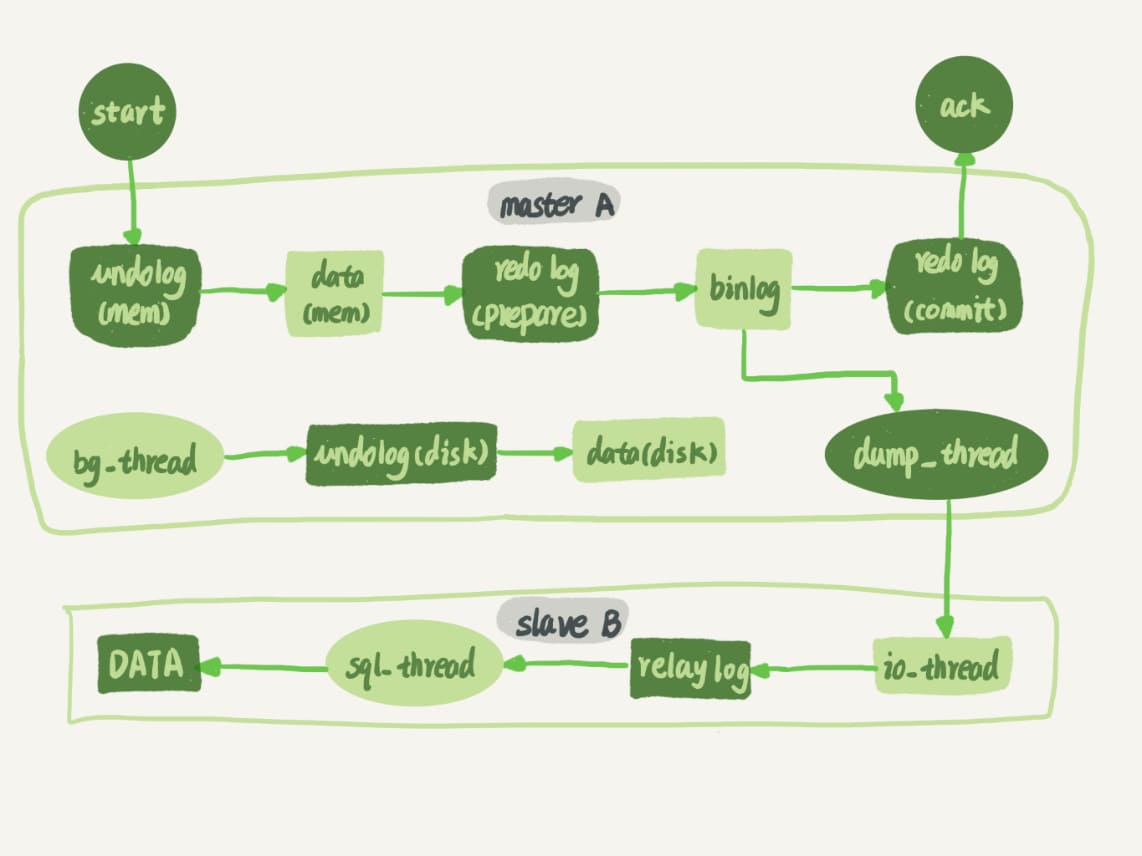
7. 主备同步
MySQL 主备同步(Master-Slave Replication)通过将主库(Master)的数据同步到备库(Slave)来实现数据的冗余和故障切换。
主备同步基于 binlog 实现的,主库将所有数据变更记录到 binlog,备库从主库拉去 binlog,解析为 SQL 语言后在备库重放,从而实现数据同步。
备库和主库之间维持了一个长连接,备库通过 change master 命令设置主库的地址、用户名密码、binlog 偏移量,然后执行 start slave 命令,启动 io_thread 线程与主库建立连接,将获取的 binlog 写到 relay log(中转日志),启动 sql_thread 线程读取 relay log 并解析命令和执行。主库内部有一个线程专用语服务备库的长连接,从指定位置读取 binlog 和发送给备库。