1. 简介
![]()
MongoDB 是一款开源的文档数据库,具有灵活的数据模型、高性能和易扩展性,常用于处理非结构化或半结构化数据的应用开发,适合需要快速迭代、数据格式多样化、追求水平扩展的项目。
官网地址:https://www.mongodb.com/
源码仓库:https://github.com/mongodb/mongo
MongoDB 的技术特性有:
- 模式灵活,无需提前定义表结构,可以随时为文档添加或删除字段,适合快速迭代和数据结构灵活多变的开发模式;
- 支持索引,可以在任何嵌套字段上创建索引,以提高查询速度;
- 支持副本,提供自动故障转移和数据容易,提高可用性;
- 支持分片,提高大数据量和高吞吐量使用场景;
- 具有强大的查询语言和聚合框架,能实现关系行数据库单表查询的大部份功能,聚合管道可以对数据进行复杂的查询操作;
- 支持多种存储引擎,默认为 WiredTiger;
MongoDB 适合的应用场景有:
- 用户数据画像:存储用户的属性、偏好、行为等,不同用户的属性差异较大;
- Web 和移动应用:存储用户生成内容、社交数据等,通过灵活的数据模型来适应变化的需求;
- 内容管理系统:存储文章、评论、标签等结构多变的内容数据;
MongoDB 不适用的场景:
- 依赖复杂事务和强一致性的系统,如金融系统;
- 需要复杂 SQL 查询和多表连接查询的场景,如 ERP、财务系统、报表系统;
- 传统商业智能 BI 和数据仓库;
- 数据模型稳定且结构规范的业务,关系行数据库的优势更大;
2. 使用
2.1 服务端
启动 MongoDB 服务端:
mongod
2.2 客户端
MongoDB 自带 JavaScript shell,可以使用命令行与服务端进行交互,它是一个功能齐全的 JavaScript 解释器,可以运行任意 JavaScript 程序。
如果有需要启动 mongo shell 时自动加载的脚本,可以添加到 .mongorc.js 文件中。
连接服务端
运行 shell,默认连接到本地的服务端 mongod,或者指定主机、端口、数据库:
mongosh
mongosh 192.168.1.1:30000/video
也可以不连接任何 mongod,启动后再连接:
mongosh --nodb
conn = new Mongo("192.168.1.1:30000")
db = conn.getDB("video")
操作
查看当前使用的数据库:
db
选择数据库 video:
use video
使用 db 变量作为当前数据库,访问集合 movie:
db.movie
一些基本的文档操作:
# 创建文档
mv = {"title":"Star Wars","year":1977}
db.movie.insertOne(mv)
# 查询文档
db.movie.findOne()
# 更新文档
db.movie.updateOne({"title":"Star Wars"},
{$set: {view: 100}})
# 删除文档
db.movie.deleteOne({"title":"Star Wars"})
执行脚本
mongo shell 可以执行指定的 JavaScript 脚本文件。
登陆后执行某个脚本然后退出:
mongosh 192.168.1.1:30000/video --quiet script1.js script2.js
可以在 mongo shell 内执行脚本:
load("script.js")
mongo shell 中还可以执行命令行程序:
run("ls", "-l")
3. 基础概念
MongoDB 中分为实例、数据库、集合、文档四层概念,前一个包含下一个概念。
3.1 文档
MongoDB 的基本数据单元是文档(Document),相当于关系型数据库中的行,它的数据格式为 BSON(Binary JSON),文档中支持嵌套其他的文档和数组,数据表示能力非常强大。
每个文档都有一个特殊的键 _id,不存在时会自动生成,默认类型为 ObjectId,也可以使用其他类型。每个文档的 _id 在所属集合中必须是唯一的,ObjectId 使得 MondoDB 能够在分片环境中生成唯一的标识符。
文档是一组有序键值的集合,可以包含多个键值对,例如:
{"greeting": "hello"}
{"greeting": "hello", "view": 3}
其中的键是字符串类型,区分大小写,文档中不能包含重复的键。
值可以是布尔、数值、字符串、数组、内嵌文档等类型。
3.2 集合
集合(Collection)是一组文档,相当于具有动态模式的表,一个集合中的文档可以拥有完全不同的字段。
集合的命名习惯通过 . 分隔不同命名空间的子集合,如 blog、blog.post 和 blog.author,但只是集合命名的管理方式,而不是真正的父子集合关系。
3.3 数据库
一个 MongoDB 实例可以拥有多个独立的数据库,每个数据库都拥有自己的集合。
通过数据库名称和集合名称连接起来,得到限定的集合名称,成为命名空间,如 db.blog。
有一些数据库名称是系统保留的:
- admin:用于身份验证和授权;
- local:单个服务器的数据存储,副本集中用于存储复制过程使用的数据;
- config:分片集群用来存储分片信息;
3.4 数据类型
MongoDB 在 JSON 基本键值对特性的基础上,增加了一些额外的数据类型支持。
null
null 类型表示空值或不存在的字段。
{"x":null}
布尔
布尔类型的值为 true 或 false。
{"x":true}
数值
数值类型默认使用 64 位浮点数。
{"x":3.14}
{"x":3}
使用 NumberInt 或 NumberLong 类来表示 4 字节和 8 字节有符号整数。
{"x":NumberInt("3")}
{"x":NumberLong("3")}
字符串
字符串类型是任何 UTF-8 字符串。
{"x":"foobar"}
日期
日期类型存储为 64 位整数,表示自 1970 年以来的毫秒数。
日期本身不会保存时区信息,会按本地时区来显示,可以用另一个键来保存时区信息。
{"x":new Date()}
正则表达式
查询时可以用正则表达式,语法和 JavaScript相同。
{"x":/foobar/i}
数组
数组是一组值,可以包含不同数据类型的元素。
MongoDB 可以深入数组内部对内容执行操作,也可以对数组内容进行更新、查询和创建索引。
{"x":["a","b","c"]}
{"x":[3.14,"pi",true]}
内嵌文档
文档内可以嵌套其他文档,被嵌套的文档就是父文档的值。
MongoDB 可以深入内嵌文档内部对内容执行操作,也可以对数组内容进行更新、查询和创建索引。
{"x":{"foo":"bar"}}
ObjectId
ObjectId 是一个 12 字节的 ID,是文档的唯一标识 _id 的默认类型。
它包含 4 字节的时间戳,5 字节的随机值,3字节的计数器(起始值随机)。时间戳和随机值保证 ObjectId 在一秒内跨机器和进程的唯一行,计数器保证单个进程 1 秒内的唯一性。
{"x":ObjectId()}
二进制数据
二进制数据是任意字节的字符串,不能通过 shell 操作,可以用来保存非 UTF-8 字符串。
代码
文档中可以存储任意的 JavaScript 代码。
{"x":function(){/* ... */}}
4. 文档操作
4.1 插入
MongoDB 对于插入操作会先执行检查:
- 如果没有 _id 字段,则会自动添加;
- 文档大小必须小于 16MB;
- 无效数据校验:包含非 UTF-8 字符串,类型无法识别等;
insertOne 插入单个文档:
db.movie.insertOne({"title":"Star War"})
insertMany 插入多个文档:
db.movie.insertMany([
{"title":"Star War1"},
{"title":"Star War2"},
{"title":"Star War3"}
])
MongoDB 3.0 之前的插入方法为 insert,新版本仍然支持,但不建议继续使用。
4.2 更新
更新操作是原子操作,如果两个更新同时发生,先执行先到达服务器的更新,再执行下一个更新。
replaceOne 将一个文档进行替换,可以在 shell 中创建另一个文档,然后替换之前的文档:
var d1 = db.user.findOne({"name": "joe"})
d1.age = 30
db.movie.replaceOne({"name":"joe"}, d1)
当匹配条件命中多个文档时,replaceOne 只会对其中的一个进行操作,有可能替换了错误的文档或者发生 _id 冲突,更建议使用 _id 作为匹配条件,查询也会更高效。
updateOne 更新一个文档,通过更新运算符来完成不同的更新操作,不过 _id 是不能改变的:
# $set 增加或修改键
db.movie.updateOne({"title":"Star War"},
{"$set":{"year":1989}})
# $unset 删除键
db.movie.updateOne({"title":"Star War"},
{"$unset":{"year":1}})
# $inc 修改键的值,不存在时创建,用于整型和浮点数
db.movie.updateOne({"title":"Star War"},
{"$inc":{"view":100}})
# $push 将元素添加到数组末尾,数组不存在时创建
db.movie.updateOne({"title":"Star War"},
{"$push":{"actor":"Mike"}})
# $addToSet 仅当数组不存在时才插入元素
db.movie.updateOne({"title":"Star War"},
{"$addToSet":{"actor":"Mike"}})
# $pop 从数组一端删除元素,key=1从末尾删除,key=-1从头部删除
db.movie.updateOne({"title":"Star War"},
{"$pop":{"key":1}})
# $pull 从数组删除匹配条件的所有元素
db.movie.updateOne({"title":"Star War"},
{"$pull":{"actor":"Tom"}})
updateMany 更新多个文档,用法和 updateOne 相同:
db.movie.updateMany({"title":"Star War"},
{"$set":{"year":1989}})
upsert 更新方式为插入更新,当文档不存在时插入,存在时更新。
db.movie.updateOne({"title":"Star War"},
{"$inc":{"view":100}},
{"upsert": true})
save 函数用于在文档不存在时插入,存在则更新。
var x = db.movie.findOne()
x.like = 10
db.movie.save(x)
4.3 删除
删除可以指定匹配条件来删除文档,也可以不指定条件。
数据删除是永久性的,无法撤回或恢复,除非从之前的备份中恢复。
deleteOne 删除一个文档:
db.movie.deleteOne({"title":"Star War","year":1983})
# 不指定条件,删除一个文档
db.movie.deleteOne({})
deleteMany 删除多个文档:
db.movie.deleteMany({"year":1984})
# 不指定条件,删除集合所有文档
db.movie.deleteMany({})
MongoDB 3.0 之前的删除方法为 remove,新版本仍然支持,但不建议继续使用。
删除集合,可以用于清空整个集合后重建集合,重建后索引会更快。
db.movie.drop()
4.4 查询
find 查询并返回文档,传递的查询值必须是常量。
# 查询所有文档
db.movie.find()
# 指定查询条件
db.movie.find({"year":1988})
指定要返回的键:
# 就算不指定 _id 也默认会返回
db.movie.find({"year":1988},{"title":1,"year":1})
# 指定不返回 _id
db.movie.find({"year":1988},{"title":1,"year":1,"_id":0})
运算符
比较运算符有 $lt $lte $gt $gte $eq $ne,用于比较范围和是否等于。
db.movie.find({"view":{"$gte":100,"$lt":200}})
db.movie.find({"year":{"$ne":1950}})
$in $nin 匹配一个键属于或排除多个值。
db.movie.find({"year":{"$in":[1988,1989]}})
一般多个条件是 AND 的关系,OR 关系通过 $or 来实现。
db.movie.find({"$or":[{"year":1900},{"title":"Star War"}]})
$not 用于排除条件。
db.movie.find({"year":{"$not":1900}})
$mod 用于计算余数,如果和第一个值取余数等于第二个值,则匹配成功。
db.movie.find({"year":{"$mod":[5,0]}})
null 可以匹配值为 null 或者键不存在,$exist 匹配键是否存在,组合起来可以匹配 null 值。
db.movie.find({"author":null})
db.movie.find({"author":{"$exists":true}})
db.movie.find({"author":{"$eq":null,"$exists":true}})
$regex 使用正则表达式来查询,后面的 i 表示不区分大小写。
db.movie.find({"title":{"$regex":/war/}})
db.movie.find({"title":{"$regex":/war/i}})
db.movie.find({"title":{"$regex":/^war/i}}) # 前缀匹配,可以利用上索引
数组
查询一个值时如果数组包含该值,也会返回。
db.food.insertOne({"fruit":["apple","banana","peach"]})
db.food.find({"fruit":"banana"})
查询使用数组的值,必须整个数组按顺序精确匹配。
db.food.find({"fruit":["apple","banana","peach"]}) # 匹配
db.food.find({"fruit":["apple","peach","banana"]}) # 不匹配
$all 匹配多个查询值都包含在数组,顺序无关紧要。
db.food.find({"fruit":{"$all":["apple","banana"]}})
可以匹配指定下标的值,下标从 0 开始。
db.food.find({"fruit.2":"banana"})
$size 匹配数组长度。
db.food.find({"fruit":{"$size":3}})
$slize 返回数组的部份切片。
db.blog.post.findOne(criteria,{"comment":{"$slice":10}}) # 前10条
db.blog.post.findOne(criteria,{"comment":{"$slice":-20}}) # 后20条
db.blog.post.findOne(criteria,{"comment":{"$slice":[100,5]}}) # 指定偏移量和数量
内嵌文档
对于以下的文档:
{
"name" :{
"first":"Donald",
"last":"Trump"
},
"age": 70
}
如果需要查询姓名:
db.people.find({"name":{"first":"Donald","last":"Trump"}})
db.people.find({"name.first":"Donald","name.last":"Trump"})
JavaScript 代码
通过 $where 来执行 JavaScript 代码,这将无法使用索引。
db.movie.find({"$where":function(){...}})
游标
使用游标来限制结果数量,或者跳过一些结果。
var cursor = db.collaction.find();
while (cursor.hasNext()) {
obj = cursor.next();
// do sth.
}
排序和分页
limit 函数用于限制结果数量。
db.movie.find().limit(10)
skip 函数用于跳过前面部份结果,如果 skip 跳过大量结果,将会导致性能问题。
db.movie.find().skip(100)
sort 函数用于给结果排序,对于键的值,1 表示升序排序,-1 表示降序排序。
db.movie.find().sort({"title":1,"year":-1})
5. 索引
未使用索引时会对集合进行扫描,使用索引可以加速集合的查询,为了提高查询速度,应该给必要的查询模式创建对应索引。
索引也会带来一定代价,对索引字段的写操作也需要同时更新索引,带来一些性能消耗。
5.1 创建索引
在指定字段创建索引,键对应的 1 表示索引在组织数据时保存为升序,-1 表示降序,升序和降序只需要创建一个即可。
db.movie.createIndex({"title":1})
在多个字段创建复合索引,查询匹配到复合索引的前缀时才能使用该索引。
db.movie.createIndex({"year":1,"title":1})
可以对对象和数组创建索引,复合索引中只能有一个字段是来自数组的,避免组合爆炸。
# 对子字段创建索引
db.movie.createIndex({"loc.city":1})
# 对数组创建索引,当数组长度较大时索引压力会较大
db.movie.createIndex({"comment.date":1})
# 对数组某一下标内部创建索引
db.movie.createIndex({"comment.10.vote":1})
唯一索引确保每个值只会在索引出现一次,_id 本身就有一个唯一索引。
当字段不存在时,索引中会存储 null,需要注意集合中多个文档在唯一索引中的字段不存在时,会因为出现多个 null 而唯一性冲突。
db.movie.createIndex({"title":1},
{"unique":true})
部份索引是只在集合的部份数据创建索引。
唯一索引和部份索引可以同时声明。
db.movie.createIndex({"title":1},
{"partialFilterExpression":{"email":{"$exists":true}}})
设计复合索引时,应该考虑到常用的查询方式,将等值过滤的键放在最前面,排序的键放在多值过滤字段前,多值过滤字段放在后面。
创建索引尽量选择值的区分度较高的字段。
每个索引都会有一个默认名字:
db.movie.createIndex({"year":1,"title":1})
# 索引名称: year_1_title_1
创建时指定索引名称:
db.movie.createIndex({"year":1,"title":1},
{"name":"movie_year_title"})
TTL 索引允许为每个文档设置一个超时时间,一个文档过期后会被删除,TTL 索引不能是复合索引。
MongoDB 每分钟扫描一次 TTL 索引删除过期文档。
db.movie.createIndex({"lastupdate":1},
{"expireAfterSeconds":60*60*24})
5.2 选择索引
MongoDB 在查询操作,会根据查询的字段,来从多个索引选择最优的。
当有多个索引被标识为该查询的候选索引,就会创建多个查询计划,并行运行这些查询,最快返回结果的一个作为选择,同样字段的查询后续也会复用该索引。
服务器会维护查询计划的缓存,以备后面执行相同的查询。时间推移、集合和索引的变化、mongod 重启都可能将查询计划从缓存清除。
查询只需要索引中的字段时,称为覆盖查询,就不再需要去加载实际文档了,无必要可以避免返回 _id 字段。
范围查询可以使用索引,$ne 查询可以使用索引,但必须扫描整个索引,$not $nin 常常退化为全表扫描,OR 查询的每个子句都可以使用索引,然后进行结果集合并去重。
查询结果集在集合中占的比例越大,索引就越低效,因为索引需要先执行一次查找索引项,再执行一次根据索引指针查找文档,而全表扫描只需要查找文档。
5.3 explain
explain 可以输出查询操作的详细信息、查询的方式、使用的索引。
db.movie.find().explain('executionStats')
返回的信息:
- stage:是否使用索引,COLLSCAN 表示集合扫描,IXSCAN 表示使用索引;
- indexName:使用的索引;
- totalKeysExamined:扫描的索引项数量;
- totalDocsExamined:扫描的文档数量;
- executionTimeMillis:查询执行的毫秒数;
- nReturned:查询返回的文档数量;
- indexBounds:索引的使用方式和遍历范围;
5.4 索引管理
数据库中所有的索引都记录在 system.indexes 集合中,可以查看已有索引的元信息。
也可以查看某个集合中的已有索引:
db.movie.getIndexes()
删除索引:
db.movie.dropIndex("year_1_title_1")
5.5 地理空间索引
GeoJSON 格式可以表示点、线和多边形。
# 点由精度和纬度组成
{
"name":"City1",
"loc": {
"type":"Point",
"coordinates": [50, 20]
}
}
# 线由点的数组表示
{
"name":"River1",
"loc": {
"type":"LineString",
"coordinates": [[0,1],[0,3],[4,4]]
}
}
# 多边形由点的数组表示
{
"name":"Country1",
"loc": {
"type":"Polygon",
"coordinates": [[0,1],[0,3],[4,4],[5,2]]
}
}
2dsphere 索引基于地球球面几何模型,考虑到地球形状,距离处理更准确。
db.map.createIndex({"loc":"2dsphere"})
2d 索引表示一个平面上的坐标,用于游戏地图、时间序列数据等。
db.map.createIndex({"loc":"2d"})
可以通过 $near $geoNear $geoWithin 等对地理空间索引进行查询。
# 矩形方框范围
db.map.find({"loc":{"$geoWithin":{"$box":[10,10],[20,20]}}})
# 圆形范围
db.map.find({"loc":{"$geoWithin":{"$center":[[40,40],5]}}})
# 多边形范围
db.map.find({"loc":{"$geoWithin":{"$polygon":[[10,10],[20,20],[10,20]]}}})
5.6 全文搜索索引
MongoDB 支持对字符串字段创建全文搜索索引,但其会消耗大量系统资源,比单字段索引、复合索引、多键索引的写操作开销更大。
创建文本索引:
db.movie.createIndex({"title":"text","body":"text"})
# 设置权重
db.movie.createIndex({"title":"text","body":"text"},
{"wweights":{"title":5,"body":2}})
# 给所有字符串字段创建全文本索引
db.movie.createIndex({"$**":"text"})
文本查询:
db.movie.find({"$text":{"$search":"hello world"}})
# 按相关性分数排序
db.movie.find({"$text":{"$search":"hello world"}},
{"title":1,"score":{"$meta":"textScore"}}).
sort("score":{"$meta":"textScore"}).limit(10)
5.7 固定集合
固定集合是固定大小的集合,插入新的文档如果满了会淘汰最旧的文档,该集合无法删除文档,无法进行导致文档大小增长的更新。
可以用于记录日志。
创建固定集合:
db.createCollection("collection",{"capped":true,"size":10000})
6. 聚合
聚合框架基于管道的概念,从集合获取输入,传递到一到多个阶段,每个阶段执行不同的操作,最后输出结果。
匹配:筛选结果
db.movie.aggregate([
{"$match": {"year":{"$gte":1900}}}
])
投射:指定输出字段
db.movie.aggregate([
{"$project": {"_id":0,"title":1,"year":1}}
])
排序
db.movie.aggregate([
{"$sort": {"view":1}}
])
跳过
db.movie.aggregate([
{"$skip": 100}
])
限制
db.movie.aggregate([
{"$limit": 10}
])
将他们组合起来:
db.movie.aggregate([
{"$match": {"year":{"$gte":1900}}},
{"$sort": {"view":1}},
{"$skip": 100},
{"$limit": 10},
{"$project": {"_id":0,"title":1,"year":1}}
])
7. 事务
MongoDB 支持跨操作、集合、数据库、文档、分片的 ACID 事务。
核心API
使用类似关系型数据库执行开启、提交事务的语句,不为大多数错误提供重试逻辑,要求开发者为操作、事务提交、错误处理编写代码。
session.start_transaction(...)
session.commit_transaction()
with client.start_serssion() as session:
try:
run_with_retry(...,session)
except Exception as exc:
# 错误处理
raise
回调API
推荐使用这种方式。
def callback(session):
...
with client.start_session() as session:
session.with_transaction(callback,...)
多文档事务只能对一存在的集合或数据库执行读写操作,不能在事务中创建集合、删除集合、进行索引操作。
7. 复制
在 MongoDB 中,创建副本集(replica set)后就可以使用复制功能了,副本集是一组服务器,其中一个是用于处理写操作的主节点(primary),还有多个保存主节点数据副本的从节点(secondary)。
当主节点崩溃了,从节点中会选取出一个新的主节点。
创建副本集,创建成功后会有 3 个 mongod 进程。
mkdir -p ~/data/rs1
mkdir -p ~/data/rs2
mkdir -p ~/data/rs3
mongod --replSet mdbDefGuide --dbpath ~/data/rs1 --port 27017 --smallfiles --oplogSize 200
mongod --replSet mdbDefGuide --dbpath ~/data/rs2 --port 27018 --smallfiles --oplogSize 200
mongod --replSet mdbDefGuide --dbpath ~/data/rs3 --port 27019 --smallfiles --oplogSize 200
在任一成员中启动副本集,它们会选举出一个主节点。
mongosh --port 27017
rsconf = {
"_id":"mdbDefGuide",
"members": [
{"_id":0,"host":"localhost:27017"},
{"_id":1,"host":"localhost:27018"},
{"_id":2,"host":"localhost:27019"}
]
}
rs.initiate(rsconf)
副本集选区主节点需要得到大多数(超过一半)节点的支持。
MongoDB 通过操作日志(oplog)在多台服务器进行数据同步,oplog 保存了主节点的每个写操作。每个从节点也都维护着自己的 oplog,也就可以被其他成员用作同步源。
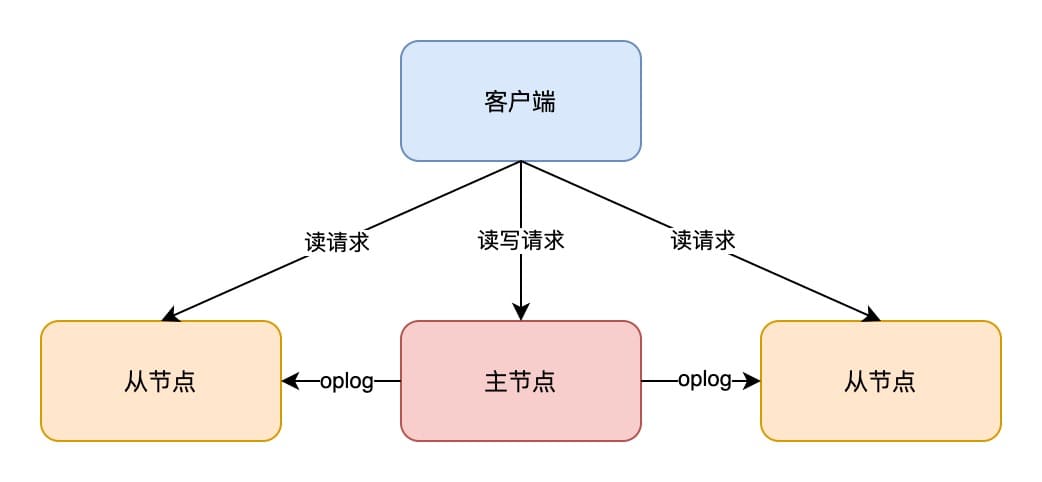
初始化同步时,会讲所有数据从副本集的一个成员复制到另一个成员,完成初始化同步后,会持续地从同步源复制 oplog,并在一个异步进程中应用操作。
所有成员每隔两秒会想副本集的其他成员发送心跳请求,用来检查每个成员的状态。
8. 分片
MongoDB 分片机制允许创建一个由多个机器组成的集群,将集合中的数据分散在集群中,每个分片拥有一个子集数据。
需要在分片的前面运行一到多个路由进程 mongos,mongos 负责客户端请求的转发和合并,配置服务器(Config Server)负责存储集群分片的元数据。应用程序的请求到达 mongos 后,mongos 负责将请求转发到对应的分片,再收集响应合并后发送回应用程序。
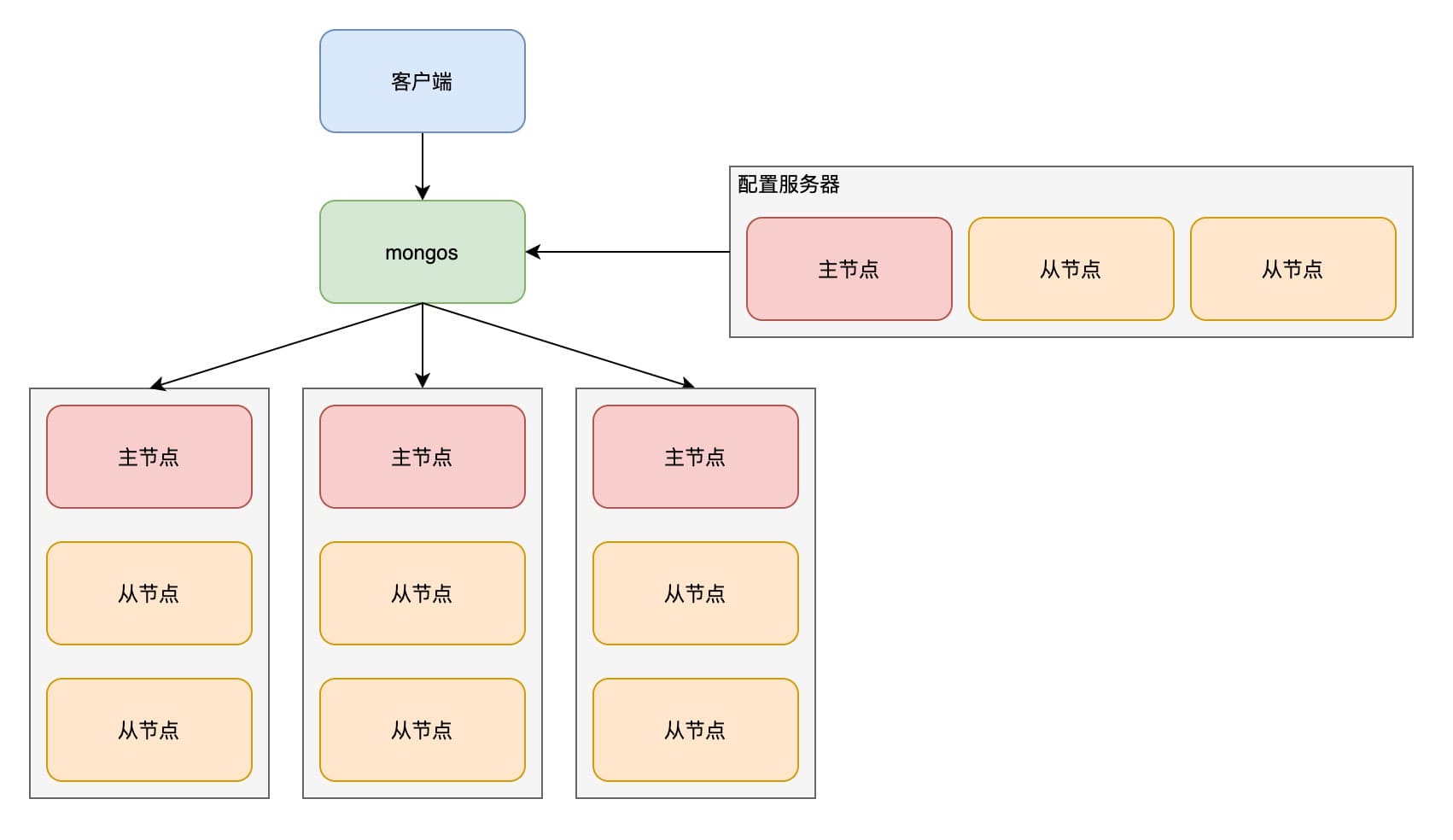
首先需要对数据库启用分片:
sh.enableSharding("video")
对集合进行分片,需要选择一个片键(shard key),片键用来拆分数据的一个或几个字段。
首先创建一个索引:
db.movie.createIndex({"title":1})
对集合进行分片:
sh.shardCollection("video.movie",{"title":1})
查询在包含片键时,发送到部份的分片称为定向查询,必须发送到所有分片的查询称为分散-收集查询/广播查询。
不应该过早分片,这回增加部署的复杂度,需要在数据量超载前进行分片处理。
分片的作用有:
- 增加可用内存;
- 增加可用磁盘空间;
- 减少服务器负载;
- 处理单个 mongod 无法承受的吞吐量;