1. 简介
MergeTree 表引擎系列是 ClickHouse 最常使用的表引擎,基础的 MergeTree 表引擎,提供了主键索引,提供了主键索引、数据分区、数据副本、数据采样等特性等基本能力,家族的其他表引擎则在此基础拥有其他额外特性,如 ReplacingMergeTree 可以删除重复数据,SummingMergeTree 会按照排序键自动聚合数据。
MergeTree 在写入一批数据时,数据会以数据片段的形式写入磁盘,且数据片段不可修改。ClickHouse 会通过后台线程定期合并这些数据片段,属于相同分区的数据片段会被合并为一个新的片段。这种数据片段往复合并的特点就是其名字的由来。
2. 建表
指定表引擎创建 MergeTree 数据表:
CREATE TABLE table_name (
name [type]
) ENGINE = MergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value [,...]]
其他配置参数:
- PARTITION BY:分区键,可以是单个或多个字段,如果不声明则生成一个名为 all 的分区;
- ORDER BY:排序键,可以是单个或多个字段,指定在一个数据片段内数据的排序标准,默认为主键;
- PRIMARY KEY:主键,会根据主键字段生成一级索引,默认和排序键相同,不再需要指定主键;
- SAMPLE BY:抽样;
- SETTINGS: index_granularity = n:索引的粒度,默认为 8192,每隔 8192 行才生成一条索引;
- SETTINGS: index_granularity_bytes = n:根据每批次写入数据的大小,动态划分间隔大小,默认为 10M,设置 0 表示不启用自适应功能;
- SETTINGS: enable_mixed_granularity_parts:设置是否开启自适应索引间隔功能,默认开启;
- SETTINGS: merge_with_ttl_timeout:数据 TTL 功能;
- SETTINGS: storage_policy:多路径的存储策略;
MergeTree 在磁盘的物理存储结构:
table_name # 表目录
├── 20250101_1_1_0 # 分区目录
│ ├── checksums.txt # 校验文件,保存其他文件的size大小和哈希值
│ ├── columns.txt # 列字段信息文件
│ ├── count.txt # 计数文件,记录当前分区下数据总行数
│ ├── primary.idx # 一级索引文件,二进制存储
│ ├── [Column].bin # 数据文件,压缩格式存储,每列分一个文件存储
│ ├── [Column].mrk # 列字段标记文件,二进制存储,保存了.bin文件的偏移量信息
│ ├── [Column].mrk2 # 如果使用了自适应大小的索引间隔,则用这个列标记文件
│ ├── partition.dat # 保存当前分区下分区表达式最终生成的值
│ ├── minmax_[Column].idx # 记录当前分区下分区字段对应原始数据的最小和最大值
│ ├── skp_idx_[Column].idx # 二级索引,二进制存储
│ └── skp_idx_[Column].mrk # 二级索引标记文件,二进制存储
├── 20250101_2_2_0
└── 20250102_3_3_0
3. 数据分区
ClickHouse 通过分区,将数据进行纵向切分,在物理上分隔成更小的单元,每个分区对应文件系统的一个目录。
分区减少了查询扫描的数据量,从而提升查询性能。
3.1 分区ID
分区 ID 生成规则:
- 不指定分区键:分区 ID 默认取名 all,所有数据写入这个 all 分区;
- 整型:按照该整形的字符形式作为分区 ID;
- 日期类型:按照 YYYYMMDD 格式化的字符形式作为分区 ID;
- 其他类型:通过哈希算法取哈希值作为分区 ID;
- 分区字段有多个:每个字段转换后用 - 连接作为分区 ID;
数据在写入时,会按照分区 ID 写到对应的数据分区。
3.2 分区目录
分区目录的命名为 PartitionID_MinBlockNum_MaxBlockNum_Level
如分区 ID 为 20250101,块编号(BlockNum)从 1 开始计数,新的分区层级(Level)为 0,则分区目录为 20250101_1_1_0。
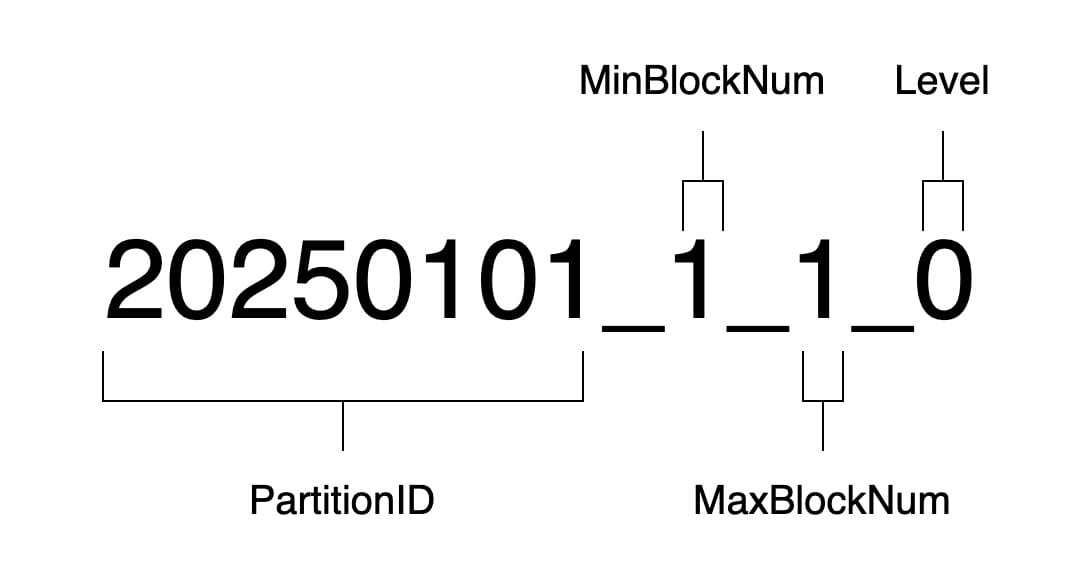
块编号在每次创建分区目录时累积加 1,分区层级在每次合并时加 1。
每一批次的数据写入,MergeTree 都会生成一批新的分区目录,对于同一个分区会存在多个分区目录。
3.3 分区目录合并
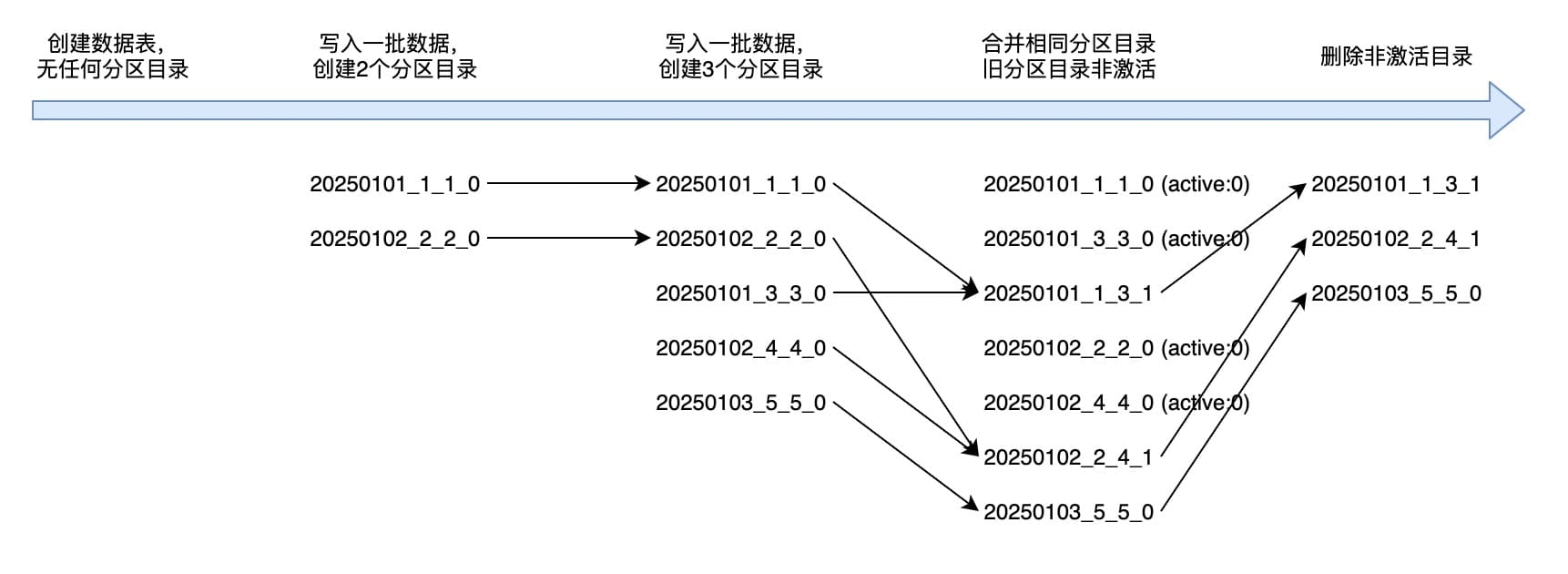
ClickHouse 通过后台任务将属于同分区的多个目录进行合并,生成新的目录,目录中的索引和数据文件也会相应地进行合并。
新的目录名称中,分区 ID 保持不变,MinBlockNum 取合并的目录中的最小 MinBlockNum 值,MaxBlockNum 取合并的目录中的最大 MaxBlockNum 值,Level 取合并的目录中最大的 Level 加 1。
分区目录在发生合并后,旧的分区目录不会立即删除,而是会保留一段时间,此时分区目录的激活状态 active = 0,在数据查询时被自动过滤掉。
以下为数据写入、分区目录合并、删除非激活状态目录的过程:
可以通过命令强制触发分区合并:
# 触发一个分区合并
optimize TABLE table_name
# 触发所有分区合并
optimize TABLE table_name FINAL
4. 数据存储
MergeTree 中数据按列存储,每个列都有一个对应的 .bin 数据文件。
数据文件是经过压缩的,默认使用 LZ4 算法,并且按照 ORDER BY 的声明排好顺序,再以压缩数据块的形式写入 .bin 文件。
.bin 文件包含多个压缩数据快,每个压缩数据块由头信息和压缩数据组成,而头信息固定使用 9 字节表示,1 字节记录压缩算法,4 字节记录压缩后的数据大小,4 字节记录压缩前的数据大小。
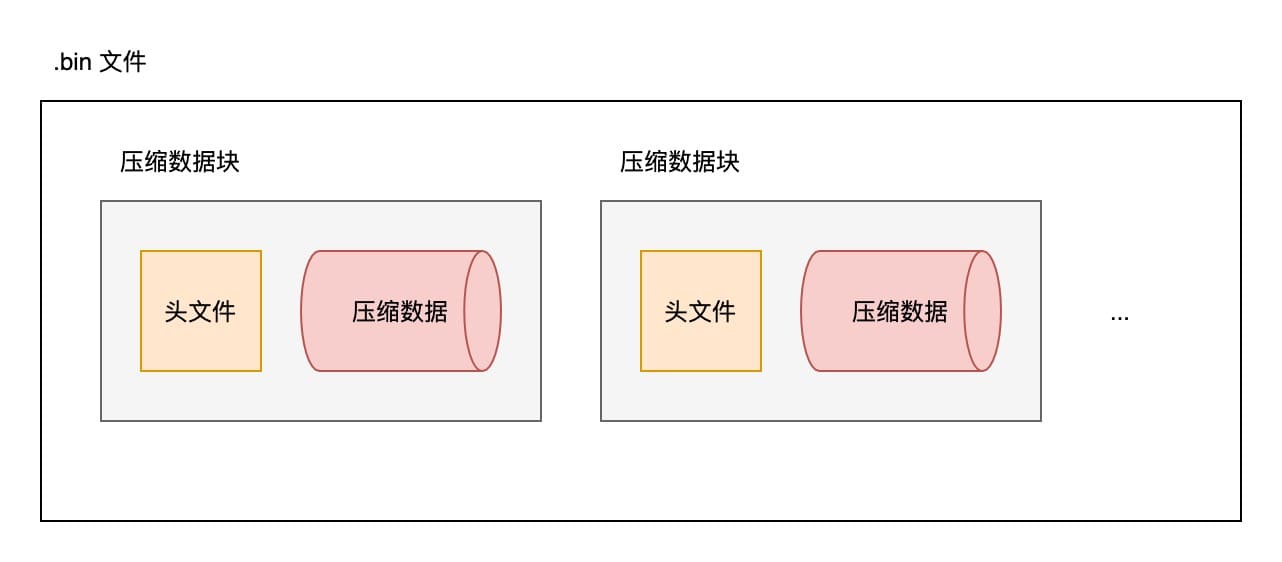
每个压缩快的体积,按压缩前的数据大小,被控制在 64KB - 1MB 之间,数据写入的批次太小则将多批次合并为一个压缩数据块,批次太大则将其拆分为多个压缩数据块。
4.1 主键索引
MergeTree 的主键使用 PRIMARY KEY 定义,然后会根据 index_granularity 间隔,默认为 8192,为数据表生成一级索引,并保存至 primary.idx 文件内,索引数据按照 PRIMARY KEY 排序。
primary.idx 文件内的一级索引采用稀疏索引实现,每一行索引标记对应的是一段数据而不是一行,仅需使用少量的索引标记就能够记录大量数据的位置信息。
因此,primary.idx 的索引数据占用空间小,常驻内存,取用速度非常快。
数据文件也按照 index_granularity 的间隔粒度生成压缩数据块。
4.2 二级索引
二级索引也称为跳数索引,由数据的聚合信息构建而成。
除了 index_granularity,二级索引还有 granularity 参数,是指一行跳数索引可以跳过多少个 index_granularity 区间的数据。
4.3 数据标记
数据标记文件为 .mrk,与 .bin 文件一一对应,用于标记 .bin 文件中数据压缩块的偏移量信息。
借助数据标记文件,无须一次性加载整个 .bin 文件,而是可以根据需要,根据偏移量只加载特定的压缩数据快。
5. MergeTree 系列表引擎
5.1 ReplacingMergeTree
ReplacingMergeTree 能够在合并分区时删除重复数据,它是以分区为单位进行去重的,不同分区之间的重复数据还不能被剔除。
创建表,ver 指定数据去重时使用的算法:
ENGINE = ReplacingMergeTree(ver)
如果没有设置 ver 版本号,则保留同一组重复数据的最后一行,如果设置了 ver 版本号,则保留 ver 字段值最大的那一行。
5.2 SummingMergeTree
SummingMergeTree 能够在合并分区的时候按预先定义的条件汇总数据,将多行数据合并为一行,用于只需要查询汇总结果,不关心明细数据的场景。
创建表,参数选填,用以指定被汇总的列字段:
ENGINE = SummingMergeTree((col1,col2,...))
如果没有指定参数,则将所有非主键的数值类型字段进行汇总。
汇总时,非汇总字段会使用第一行的取值。
5.3 AggregatingMergeTree
AggregatingMergeTree 在合并分区时,按照预先定义的条件聚合数据,是 SummingMergeTree 的升级版。
创建表:
ENGINE = AggregatingMergeTree()
表字段定义时需要声明聚合函数,可以选择 uniq、sum,决定了合并时该字段如何聚合。
5.4 CollapsingMergeTree
CollapsingMergeTree 通过以增代删的思路,支持行级数据的修改和删除,它定义一个 sign 标记字段记录数据行的状态,1 表示 有效数据,-1 表示需要被删除,在分区合并时 sign 为 1 和 -1 的一组数据将会被删除。
创建表:
ENGINE = CollapsingMergeTree(sign)
参数 sign 指定一个 Int8 类型的标记位字段。
只有相同分区内的数据才可能被折叠,且要求 sign=1 和 sign=-1 的数据相邻,因此需要按照严格顺序写入。
5.5 VersionedCollapsingMergeTree
VersionedCollapsingMergeTree 也支持数据折叠删除,但不要求数据吸入顺序。
创建表:
ENGINE = VersionedCollapsingMergeTree(sign,ver)