1. 简介
![]()
ClickHouse 是一款开源的列式存储的在线分析处理(OLAP,online analytical processing)数据库管理系统,专为大规模数据分析和实时查询而设计。
它由 Yandex 为应对海量数据分析需求而开发,全称是 Click Stream,Data WareHouse,最初用来采集点击数据产生的事件,并进行数据分析。
ClickHouse 的技术特性有:
- 采用列式存储模型,同列数据紧密排列,优化压缩和扫描效率;
- 实时查询性能高,借助向量化执行、多线程并行执行、稀疏索引等技术,快速查询大批量数据;
- 支持分片和副本,可以集群化部署并水平扩展;
- 兼容 SQL 常用语法和函数;
- 对数据进行压缩,节省存储空间;
- 支持 MergeTree、Log、Integration 等表引擎;
ClickHouse 适用的场景有:
- 商业智能领域实时 BI 报表;
- 日志事件数据分析、用户行为分析、广告效果分析;
- 数据挖掘;
ClickHouse 不适合的场景:
- 不支持 OLTP 事务;
- 联表查询支持较弱;
- 不适用于高并发随机更新或删除场景;
- 不擅长按行粒度的查询或删除操作;
2. 架构
2.1 核心特性
ClickHouse 采用 MPP 架构(massively parallel processing,大规模并行处理),通过将数据和计算任务分布到多个节点上进行并行处理,实现海量数据的高性能分析查询,它的设计目的就是以最快的速度进行 GROUP BY 查询和过滤。
ClickHouse 是一款列式存储数据库,数据按列组织,同一列的数据被保存在一起,每个列保存在不同的文件,这带来两点优势:
- 按列存储可以减少查询时所需扫描的数据量;
- 利于数据压缩,同一列的数据重复项多,压缩率更高,默认使用 LZ4 算法进行压缩;
ClickHouse 使用向量化执行引擎,利用了 CPU 的 SIMD 指令(single instruction multiple data),单条指令操作多条数据,在 CPU 寄存器层面实现数据并行操作。
ClickHouse 使用了关系型数据库相同的概念,如数据库、表、视图、函数等,完全使用 SQL 作为查询语言,容易理解和学习。
ClickHouse 支持分区,利用多线程来纵向扩展,将数据纵向切分,放到不同的独立目录。也支持分片,利用分布式来横向扩展,将数据分布到多个机器上。
ClickHouse 采用 Multi-Master 多主架构,集群中的每个节点都是主节点,适用于多数据中心、异地多活的场景。
2.2 架构设计
ClickHouse 架构核心模块如下:
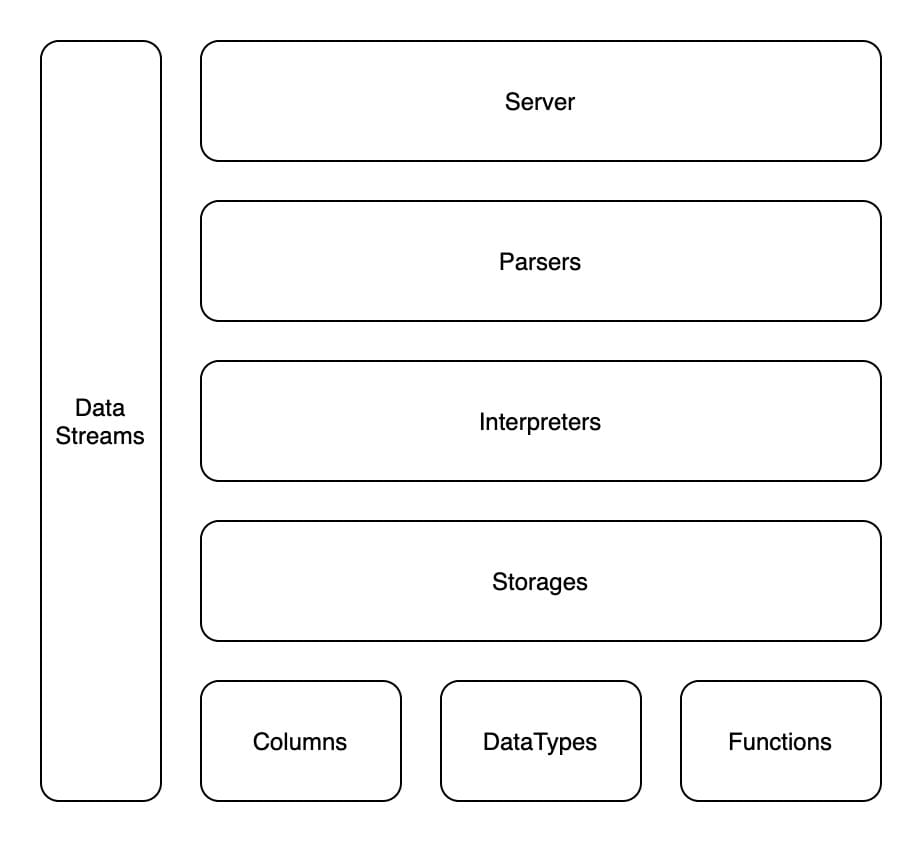
Colume
内存中的一列数据由一个 Colume 对象表示,分为接口和实现两部份,IColumn 接口定义了对数据进行各种关系运算的方法,这些方法根据数据类型不同,由响应的对象实现。
Field
Field 对象表示一个单值,该对象内部聚合了 Null、UInt64、String、Array 等数据类型和处理逻辑。
DataType
DataType 负责数据的序列化和反序列化工作,IDataType 接口定义了许多正反序列化的方法,涵盖了二进制、文本、JSON、XML、CSV、Protobuf 等格式类型。
Block
ClickHouse 内部的数据操作是面向 Block 对象进行的,且采用了流的形式。Block 对象可以看作数据表的子集,它是由 Colume、DataType、列名称组成。
Table
数据表底层设计并没有 Table 对象,直接使用 IStorage 接口指代数据表。IStorage 对 Table 发起的操作语句,根据 AST 查询语句,返回指定列的数据,再讲数据交给 Interpreter 做进一步处理。
Parser
Parser 分析器负责将一条 SQL 语句解析并创建 AST 对象。
Interpreter
Interpreter 解释器负责解析 AST 对象,执行分支判断、设置参数、调用接口等逻辑,返回 IBlock 对象,以线程的形式建立一个查询执行管道。
Function
ClickHouse 提供两种函数:
普通函数(Function)由 IFunction 接口定义,有数十种函数实现,函数作用于每行数据,是无状态的,将会采用向量化的方式批量作用计算。
聚合函数(Aggregate Function)由 IAggregateFunction 接口定义,它是由状态的,聚合函数的状态支持序列化和反序列化,可以在分布式节点之间进行传输,实现增量计算。
3. 数据定义
3.1 数据类型
数值
整数有 Int8、Int16、Int32、Int64、UInt8、UInt16、UInt32、UInt64,它们分别是有符号和无符号的不同字节大小类型。
浮点数有 Float32、Float64,表示的精度不同。
浮点数支持正无穷 inf、负无穷 -inf、非数字 nan。
定点数有 Decimal32、Decimal64、Decimal128,声明为 Decimal(P,S),P 表示总位数,S 表示小数位数,也可以简写为 Decimal(S)。
字符串
字符串 String 长度不限,无须声明大小。
FixStrring 表示固定长度字符串,通过 FixedString(N) 声明,会用 null 字节填充末尾
UUID 也是一种类型,长度为 32 位,格式为 8-4-4-4-12。
时间
DateTime 类型包含时分秒信息,精度为秒。
DateTime64 类型包含时分秒信息,精度为亚秒。
Date 类型精度为天。
数组
数组可以定义为 array(T) 或 [T]。
查询时不需要声明元素类型,ClickHouse 会推断类型,并使用最小可表达的数据类型。各元素的类型必须兼容,否则会报错。
定义表时需要指定明确元素类型。
元组
元组定义为 tuple(T) 或 (T)。
同样查询时不需要声明元素类型,各元素类型可以不同,定义表时则需要指定明确元素类型。
枚举
枚举有 Enum8、Enum16,固定使用 (String:Int) 的键值对定义,值类型分别对应 Int8 和 Int16。
在数据写入时,会对照枚举列进行检查。
嵌套类型
嵌套类型只支持一级。
Nullable
Nullable 是一种修饰符,表示字段可以被写入 Null 值,只能和基础类型使用,不能作为索引字段。
包含 Nullable 的数据表查询和写入性能会变慢,应该慎用。
域名
域名类型分 IPv4、IPv6,本质上是 UInt32 和 FixedString(16) 的封装。
3.2 数据库
创建数据库:
CREATE DATABASE [IF NOT OEXISTS] <db_name> [ENGINE = <engine>]
目前支持的引擎:
- Ordinary:默认引擎,绝大多数情况都使用,无须声明;
- DICTIONARY:字段引擎,会自动为所有数据字典创建数据表;
- Memory:内存引擎,用于存放临时数据;
- Lazy:日志引擎,智能使用 Log 系列表引擎;
- MySQL:MySQL 引擎,自动拉取远端 MySQL 的数据;
数据库会在磁盘上创建一个文件目录。
查看数据库列表:
SHOW DATABASES
删除数据库:
DROP DATABASE [IF EXISTS] <db_name>
3.3 表
创建表:
CREATE TABLE [IF NOT OEXISTS] [<db_name>.]<table_name> (
<name> [<type>] [DEFAULT|MATERIALIZED ALIAS expr]
) ENGINE = <engine>
查看表结构:
DESC <table_name>
删除表:
DROP TABLE [IF EXISTS] [<db_name>.]<table_name>
创建临时表:
临时表只支持 Memory 表引擎,会话结束后销毁,不属于任何数据库,且优先级大于普通表,存在同名时优先读取临时表。
CREATE TEMPORARY TABLE ...
创建视图:
普通视图不存储数据,只是一层查询代理,物化视图拥有独立的存储。
CREATE [MATERIALIZED] VIEW [IF NOT OEXISTS] [<db_name>.]<view_name> AS SELECT ...
另外还可以通过 ALTER TABLE 修改表结构,通过 RENAME TABLE 重命名表,TRUNCATE TABLE 清空表数据。
3.4 分区操作
查询某张表的分区信息:
SELECT partition_id,name,table,database FROM system.parts WHERE table = 'partition_v2'
删除分区:
ALTER TABLE <tb_name> DROP PARTITION <partition_id>
复制分区数据,要求两张表有相同的表结构和分区键:
ALTER TABLE B REPLACE PARTITION <partition_id> FROM A
重置某列数据为初始值:
ALTER TABLE <tb_name> CLEAR COLUMN <column_name> IN PARTITION <partition_id>
卸载分区:
ALTER TABLE <tb_name> DETACH PARTITION <partition_id>
装载分区:
ALTER TABLE <tb_name> ATTACH PARTITION <partition_id>
3.5 数据操作
插入操作:
INSERT INTO <tb_name> [(c1,c2,c3,...)] VALUES (...),(...),...
# 从查询导入
INSERT INTO <tb_name> [(c1,c2,c3,...)] SELECT ...
# 从文件导入
INSERT INTO <tb_name> [(c1,c2,c3,...)] FORMAT <format_name> <data_set>
删除操作:
ALTER TABLE <tb_name> DELETE WHERE <expr>
修改操作:
ALTER TABLE <tb_name> UPDATE <column>=<value> [,...] WHERE <expr>
ClickHouse 的修改和删除是一种很重的操作,更适用于批量修改和删除,且不支持事务,修改无法会滚,且这是一个异步后台过程,语句被提交会立即返回。
5. 查询
ClickHouse 完全使用 SQL 作为查询语言,以 SELECT 查询语句的形式获取数据。
应该只获取必要的列,尽量避免 SELECT * 查询数据,会很消耗性能。
目前支持的查询子句如下:
[WITH expr | (subquery)]
SELECT [DISTINCT] expr
[FROM [db.]table | (subquery) | table_function] [FINAL]
[SAMPLE expr]
[[LEFT] ARRAY JOIN]
[GLOBAL] [ALL|ANY|ASOF] [INNER | CROSS | [LEFT|RIGHT|FULL [OUTER]]] JOIN
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr] [WITH ROLLUP|CUBE|TOTALS]
[HAVING expr]
[ORDER BY expr]
[LIMIT [n[,m]]]
[UNION ALL]
[INTO OUTFILE filename]
[FORMAT format]
[LIMIT [offset] n BY columns]
WITH 子句:
WITH 10 AS start
WITH SUM(databyte) AS bytes
WITH (
SELECT ...
) AS total_bytes
FINAL 修饰符用于在查询过程中进行表引擎合并,会降低查询性能,避免使用。
SAMPLE 子句返回采样数据而不是全部数据,减少查询负载。
采样因子为 0 - 1 的小数,采样因子为 0.1 时将统计结果乘以 10:
SELECT count() * 10 FROM hits SAMPLE 0.1
采样样本数量为大于 1 的整数:
SELECT count() FROM hits SAMPLE 10000
PREWHERE 智能用于 MergeTree 系列表引擎,看作是对 WHERE 的优化,查询时只会读取 PREWHERE 指定的列字段,用来过滤数据,然后在读取 SELECT 的列字段补充属性,在某些场合相比 WHERE 处理的数据量更少,性能更高。
WITH ROLLUP 按照聚合键从右向左汇总上卷数据,一次生成分组小记和总计。
WITH CUBE 基于聚合键的所有组合生成小记信息。
WITH TOTALS 会基于聚合数据对所有数据进行总计,附加在后面。
6. 副本
副本是在表级别定义的,只有 ReplicatedMergeTree 表引擎可以使用副本能力,需要登陆各个节点并用 CREATE 语句创建该表。
ReplicatedMergeTree 表定义,同一个分区之间的 zk_path 相同,replica_name 不同。
ENGINE = ReplicatedMergeTree(zk_path,replica_name)
由于采用多主架构,可以在任一副本上执行 INSERT 和 ALTER 操作。
副本依赖于 ZooKeeper 的分布式协同能力,每个 ReplicatedMergeTree 表会在 zk_path 路径创建一组监听节点,通过 ZooKeeper 事件监听机制实现各个副本间的协同。
7. 分片
ClickHouse 的每个服务节点都是一个 shard(分片),数据分片需要结合 Distributed 表引擎使用。
Distributed 表引擎自身不存储数据,而是作为分布式表的一层透明代理,在集群内自动进行数据的写入、分发、查询、路由。
拥有 2 个分片,每个分片有 1 个副本的配置:
<sharding_ha>
<shard>
<replica>
<host>1.com</host>
<port>9000</port>
</replica>
<replica>
<host>2.com</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>3.com</host>
<port>9000</port>
</replica>
<replica>
<host>4.com</host>
<port>9000</port>
</replica>
</shard>
</sharding_ha>
加入集群配置后,可以使用分布式 DDL 执行表操作,ClickHouse 会根据集群配置信息,分别去各个节点执行 DDL 语句。
CREATE|DROP|RENAME|ALTER TABLE ON CLUSTER cluster_name
分布式 DDL 语句也需要借助 ZooKeeper 的协同能力,实现日志分发。
Distributed 表引擎的定义:
ENGINE = Distributed(cluster,database,table [,sharding_key])
在收到 SELECT 查询时,会依次查询每个分片的数据,再合并汇总后返回。